Lecture 16: When validation isn’t enough
MSE 125 — Applied Statistics
Wednesday, May 20, 2026
the data: US monthly retail sales
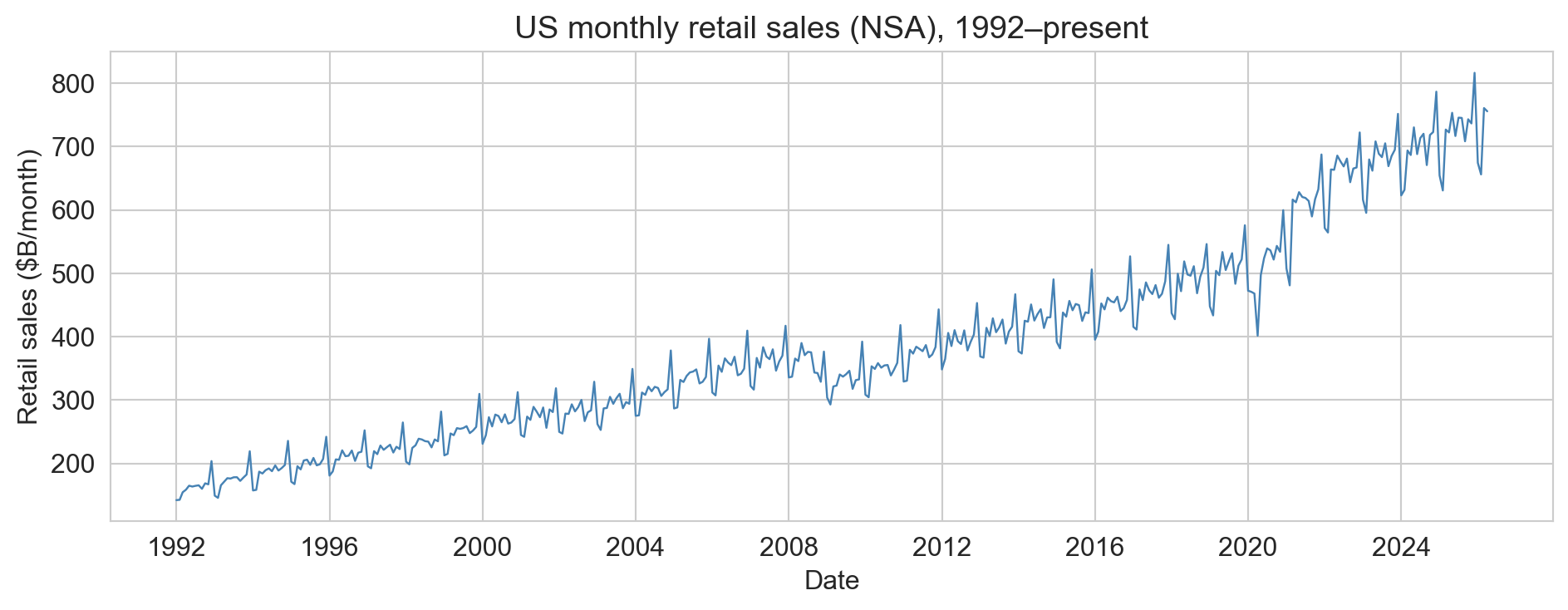
US Census / FRED series RSAFSNA, not seasonally adjusted
- long-run trend: sales grow with population, prices
- annual cycle: sharp December spike, January trough
- short-range autocorrelation: this month ≈ last month
same data, two ways to split
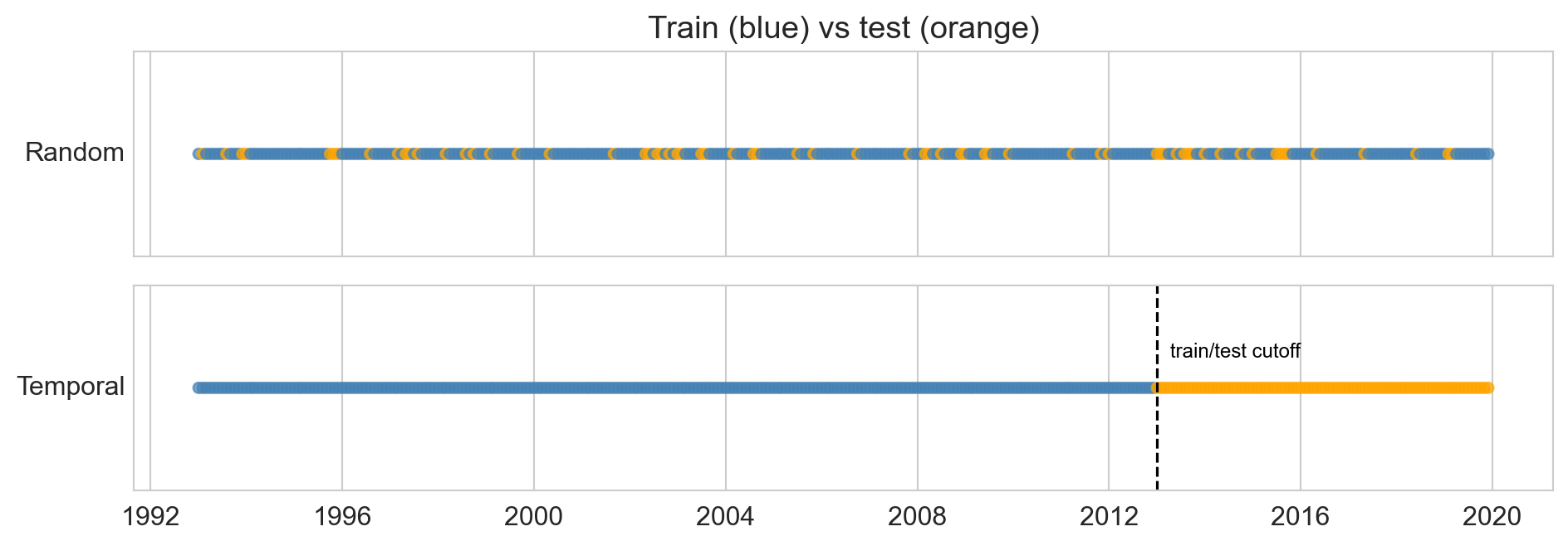
- random: shuffle all months, hold out 20%
- temporal: train early years, test later ones
when does the model break?
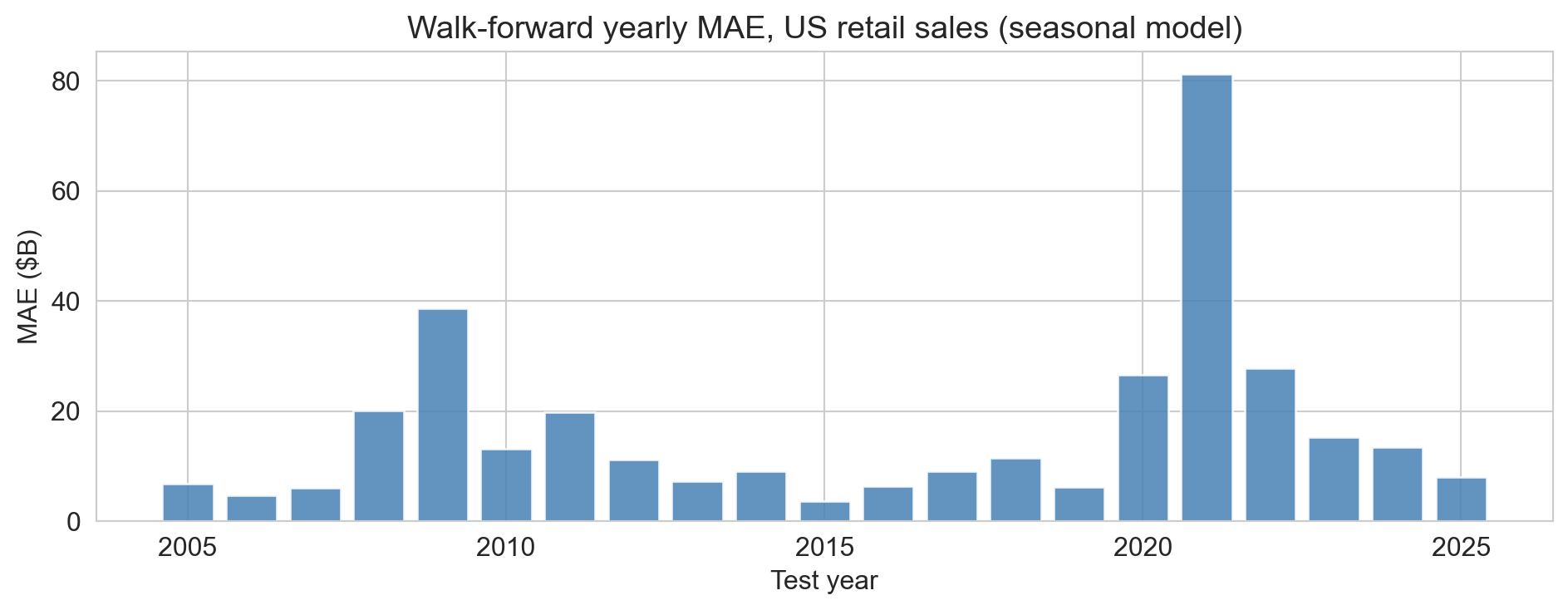
- low error through the calm years
- spikes: 2008–09 crisis, far larger 2020 pandemic
- a single average MAE would bury these regime changes
decompose: trend × seasonal × residual
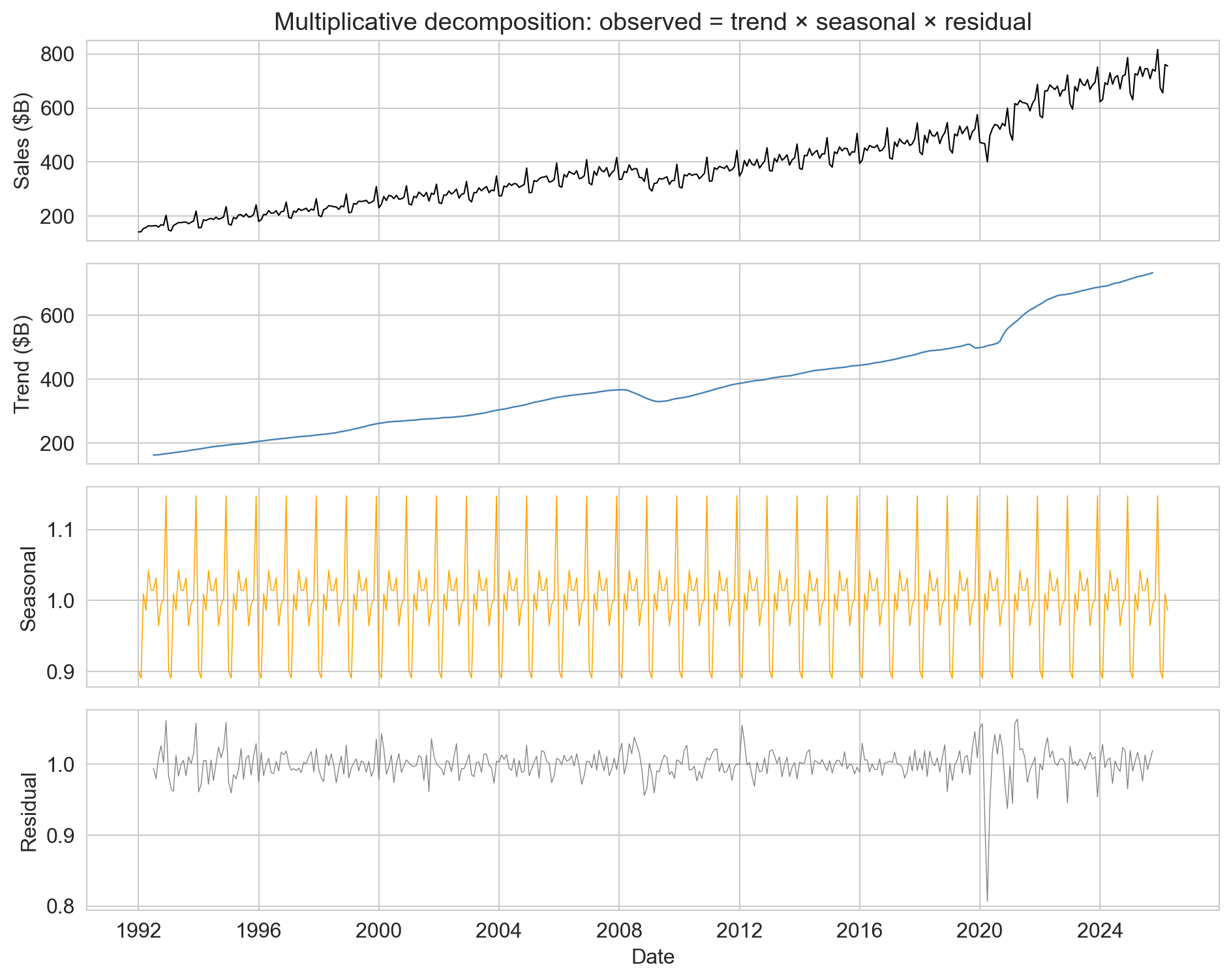
- multiplicative: December is the same percentage above trend each year
- seasonal multiplier: Dec 1.147 (+15% above trend), Feb 0.891
- residual small except the COVID crater
the forecast, and the verdict
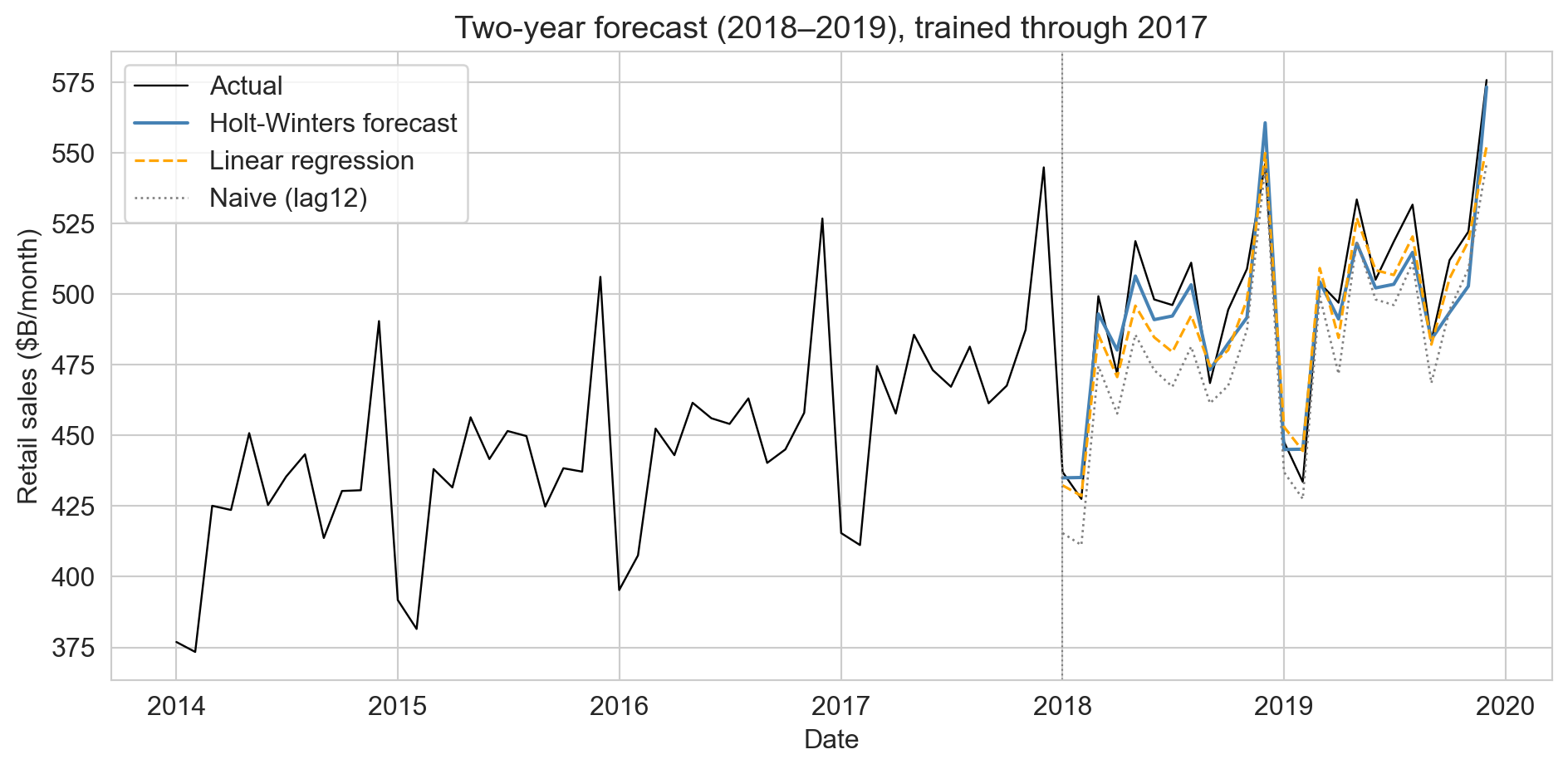
Model R² MAE
Naive (lag12) 0.672 $18.2B
Linear regression (lag12+trend) 0.894 $9.5B
Holt-Winters 0.907 $9.0BHolt-Winters wins by tracking the December multiplier. but a better model still doesn’t fix validation: COVID breaks any fit trained through 2019
the data: California daily AQI
retail had clean repeating structure. now a series with almost none
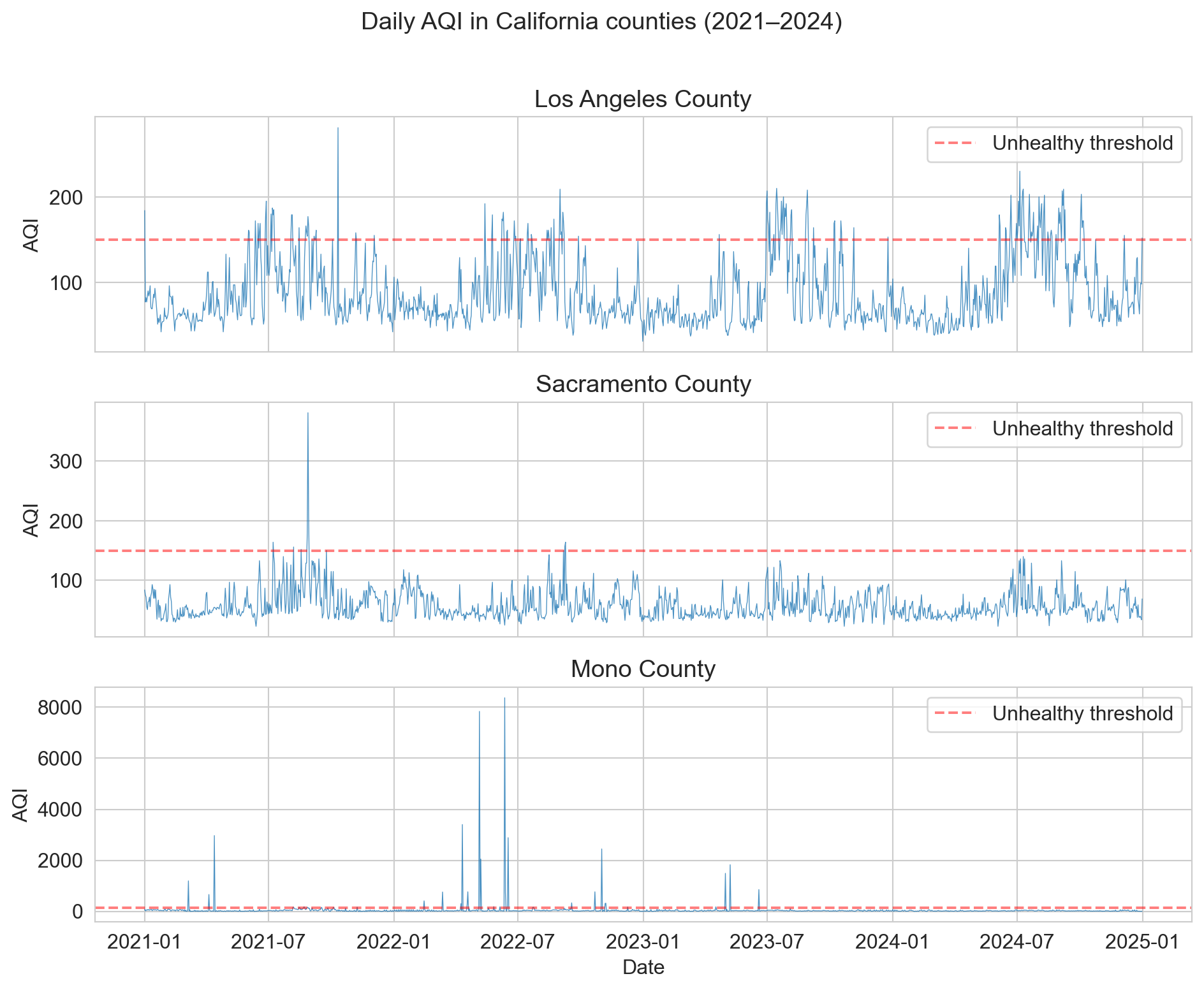
- LA, Sacramento: seasonal wildfire spikes on baseline pollution
- Mono County: dust storms push AQI above 8,000
- AQI: 0 clean → 150 unhealthy → 500 hazardous
the model flatlines
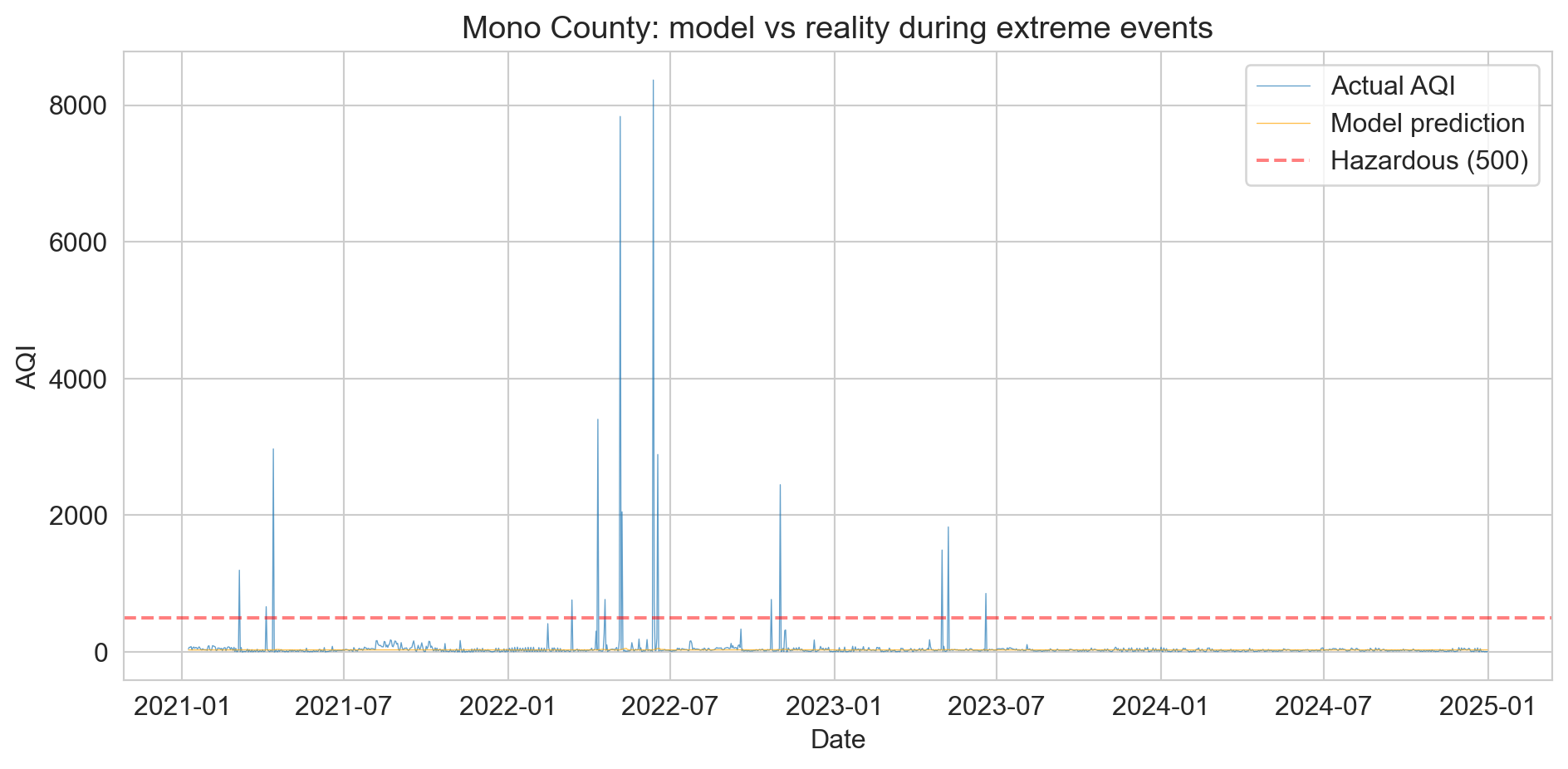
selected extreme days
Actual AQI Predicted Error
7835 30 7805
3404 30 3374
1196 29 1167coefficient on yesterday’s AQI ≈ −0.0004
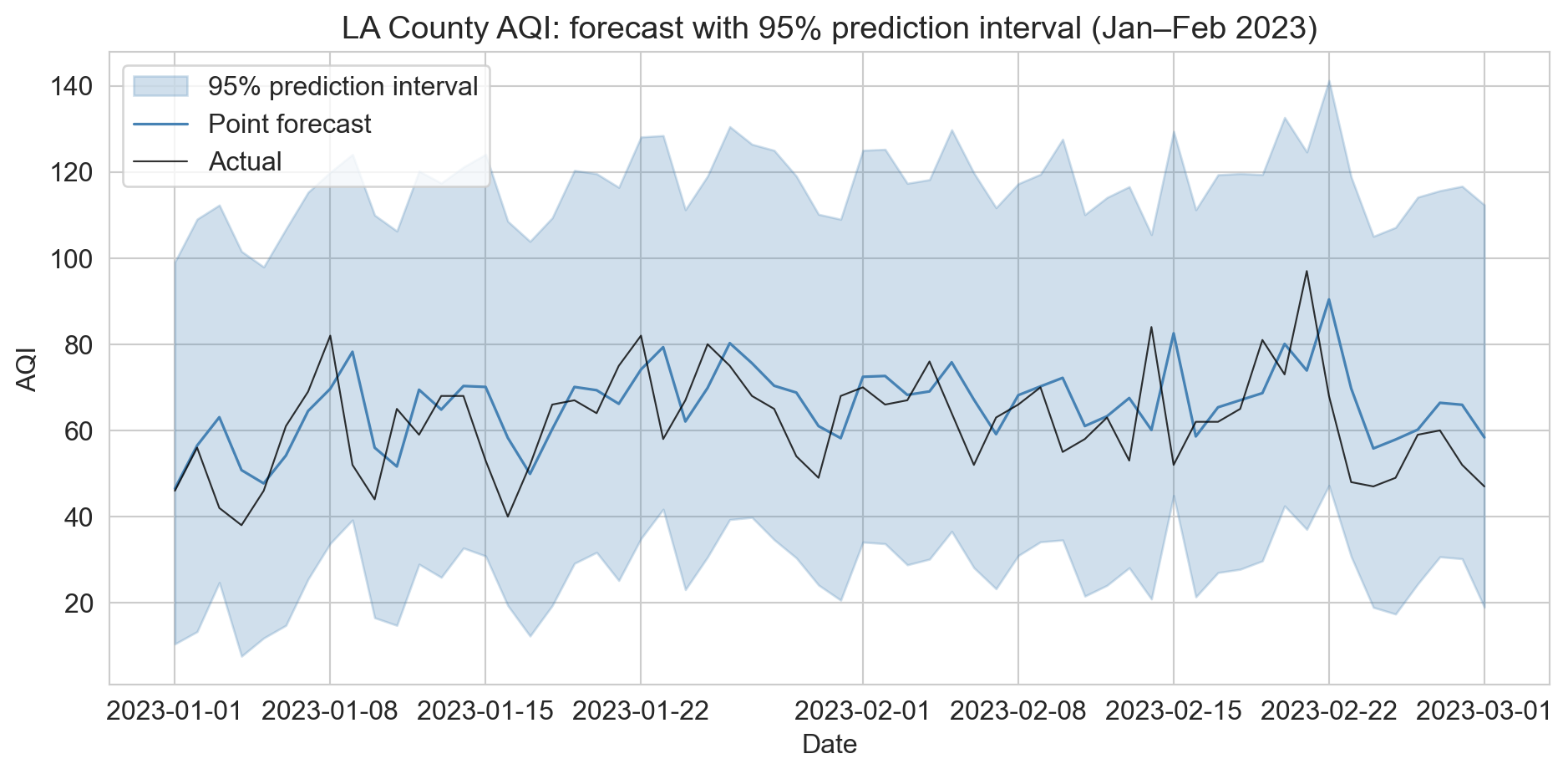
report a range, not a point
- bootstrap from Chapter 8: resample training residuals, add to each forecast
- works for any model: 95% interval here, coverage 93.7%, width 89.5 AQI
- widens for ordinary noise, but blind to regimes never seen (Mono blew past it)
predictive policing

Photo: Mr. Satterly / Wikimedia Commons, CC0
- model flags neighborhood as high-crime
- police patrol it harder
- more patrols → more arrests
- model retrains, “confirms” itself
. . .
the model creates the data that justifies it
a causal arrow runs backward
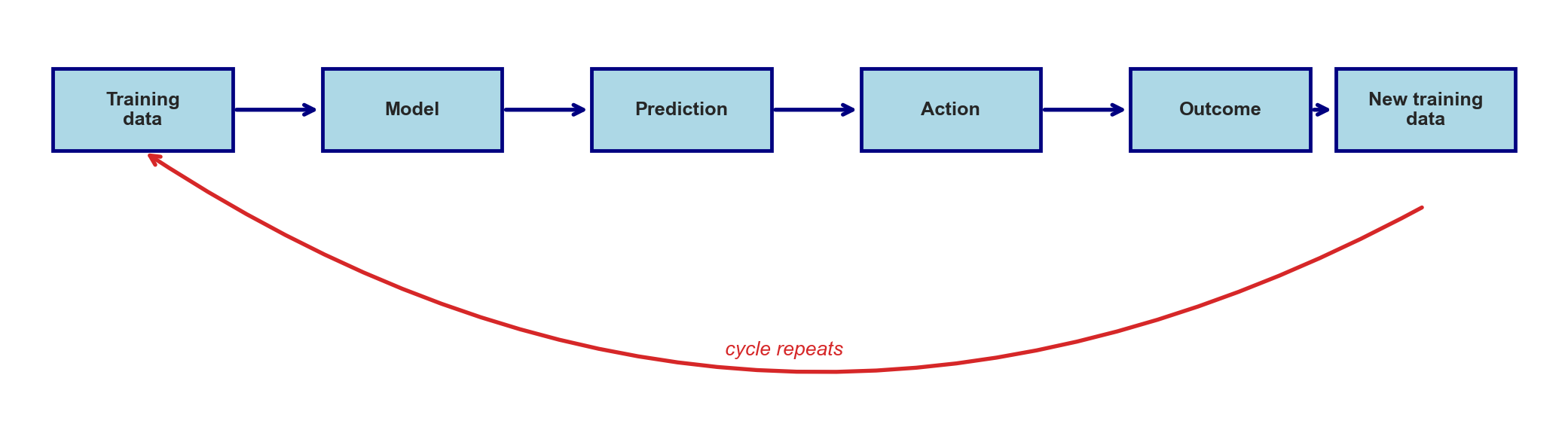
prediction → action → outcome → new training data → repeat
Weapons of Math Destruction

Photo: GRuban / Wikimedia Commons, CC BY-SA 4.0
three traits together make a WMD:
- outcome not easily measurable
- negative consequences for individuals
- self-fulfilling feedback loop
Cathy O’Neil, Weapons of Math Destruction (2016)
emissions testing

- VW software detected the EPA lab cycle
- full emissions controls only during the test
- on the road: NOx up to ~40× the legal limit
. . .
optimized the test exactly. real-world emissions moved the opposite way
Photo: Mario R. Duran Ortiz / Wikimedia Commons, CC BY-SA 3.0; EPA Notice of Violation 2015
school accountability tests

when evaluations hinge on scores:
- Chicago: answer-altering in ≥ 4–5% of classrooms
- Florida: weak students reclassified as test-exempt
. . .
the score rises without learning rising
Photo: dcJohn / Wikimedia Commons, CC BY 2.0; Jacob & Levitt 2003, Figlio & Getzler 2002
p-hacking
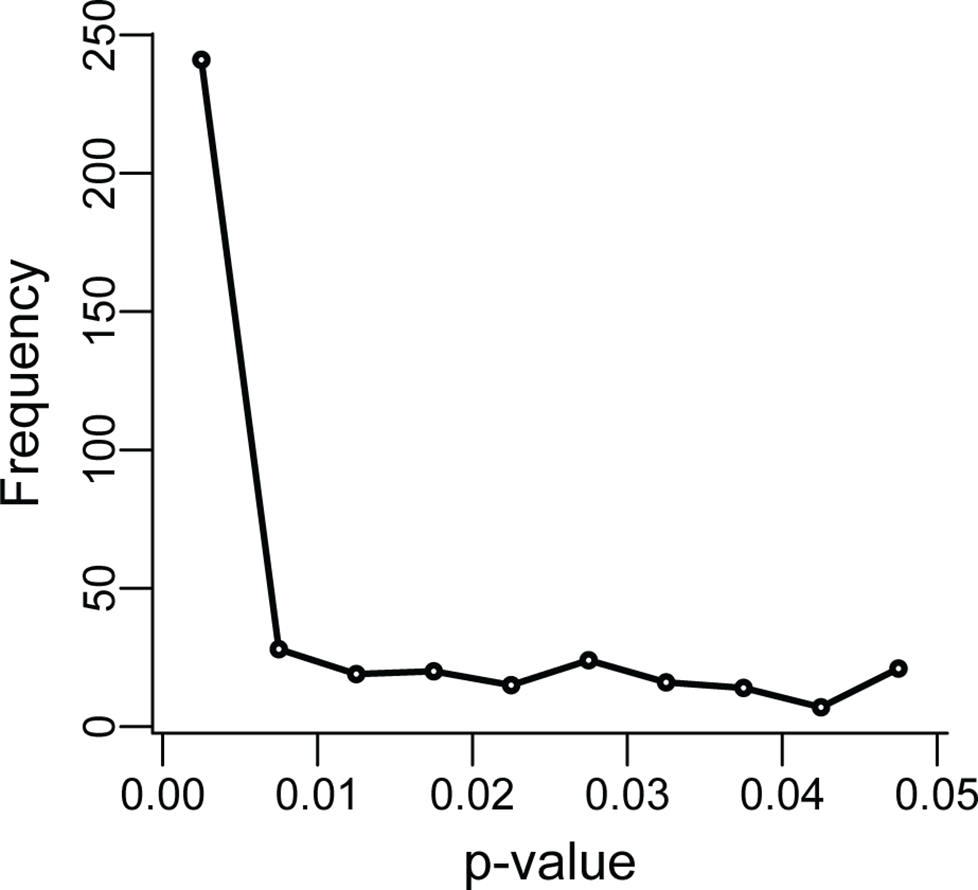
Head et al., PLOS Biology 2015, CC BY 4.0
- p < 0.05 meant to gauge evidence
- careers depend on clearing it
- researchers exploit “degrees of freedom”
. . .
a tell-tale excess of p-values just below 0.05
feedback

what worked? what didn’t? what’s still confusing?