Lecture 15: Clustering with K-Means
MSE 125 — Applied Statistics
Monday, May 18, 2026
the brief
Pacers front office
goal: sign a wing who can space the floor and attack closeouts
the five-position label is no help: Curry and Westbrook are both “point guards” and play nothing alike
what is the real taxonomy of NBA players in 2024?
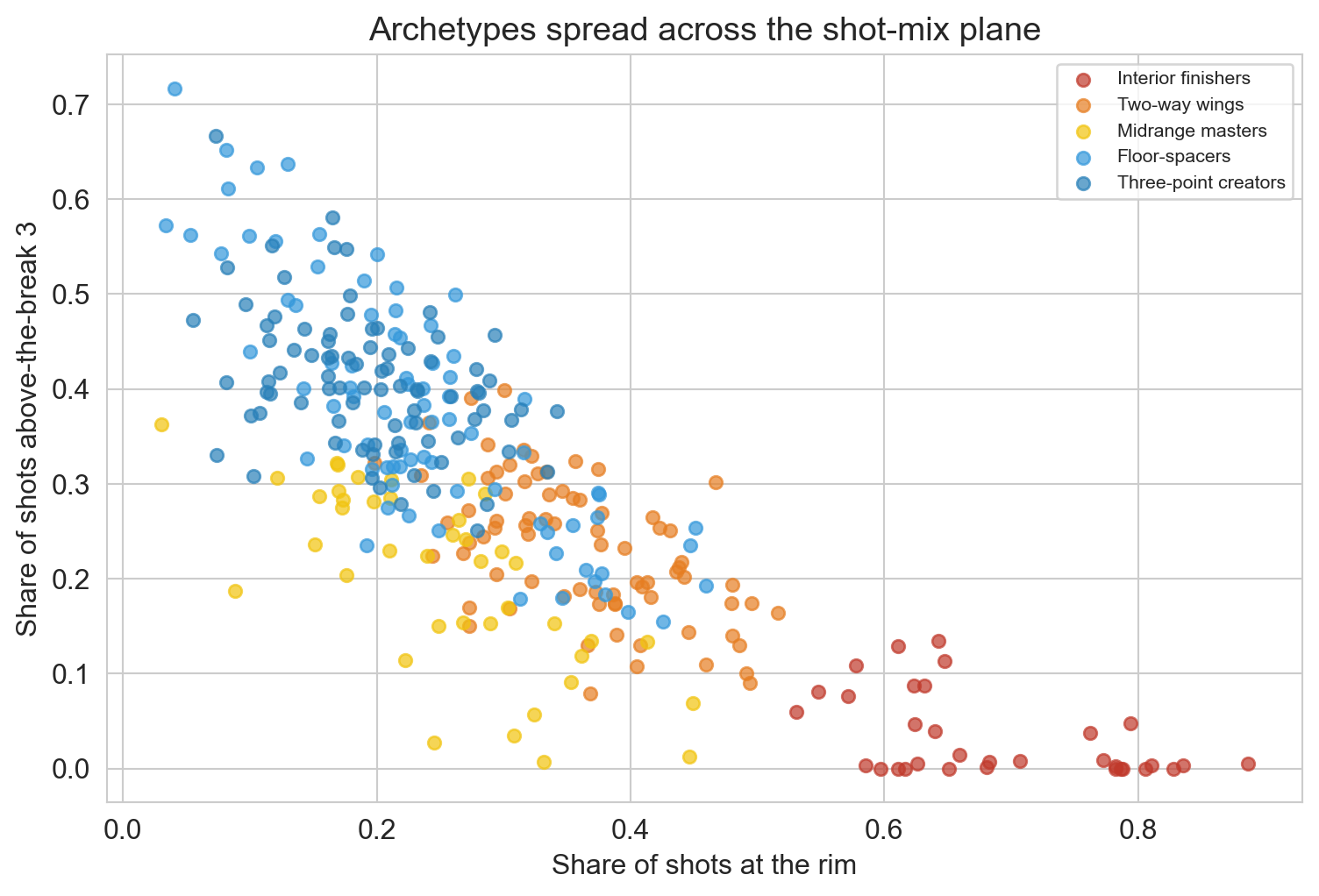
famous pairs
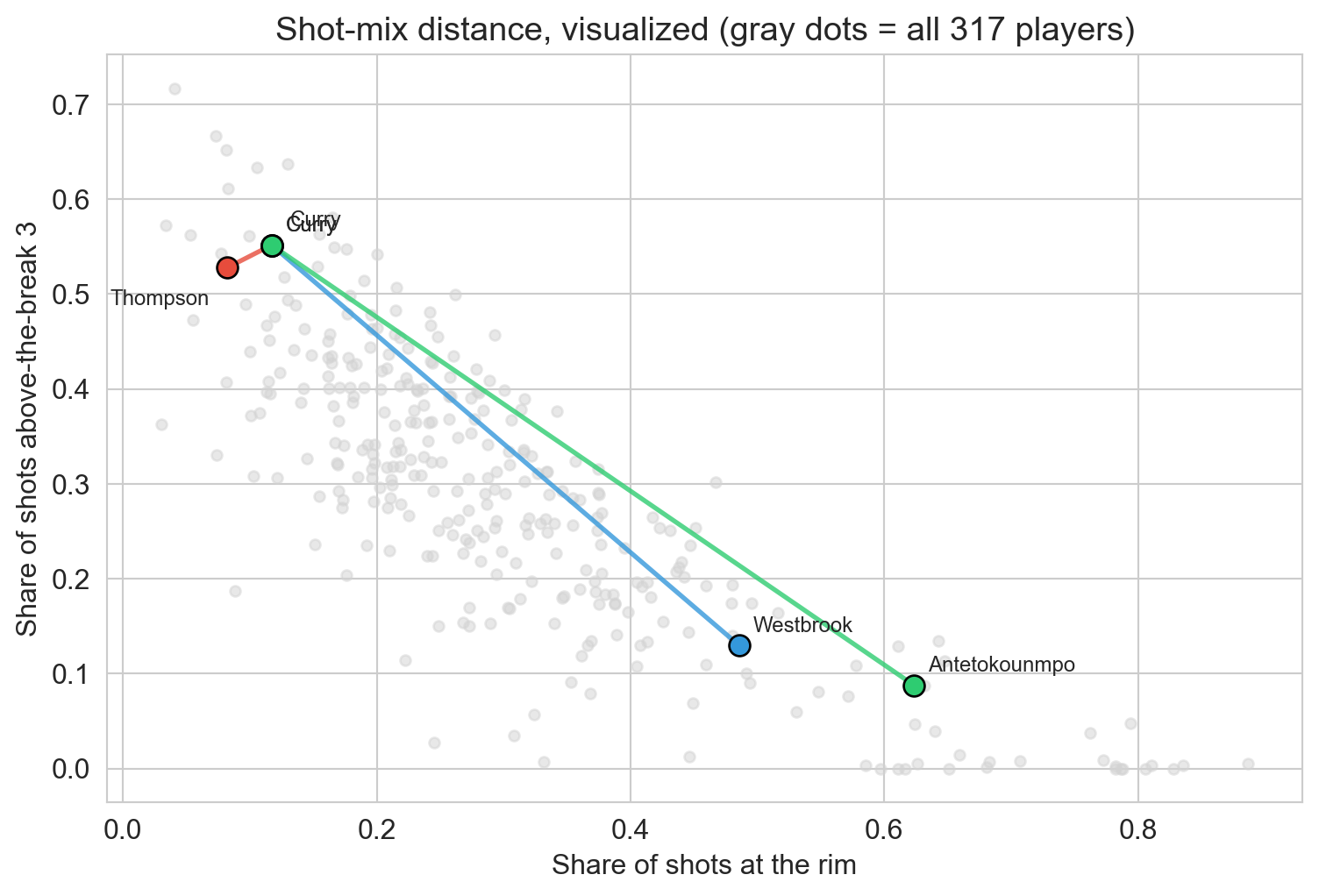
gray dots = all 317 players. colored lines = three famous pairs in shot-mix distance.
watch it iterate
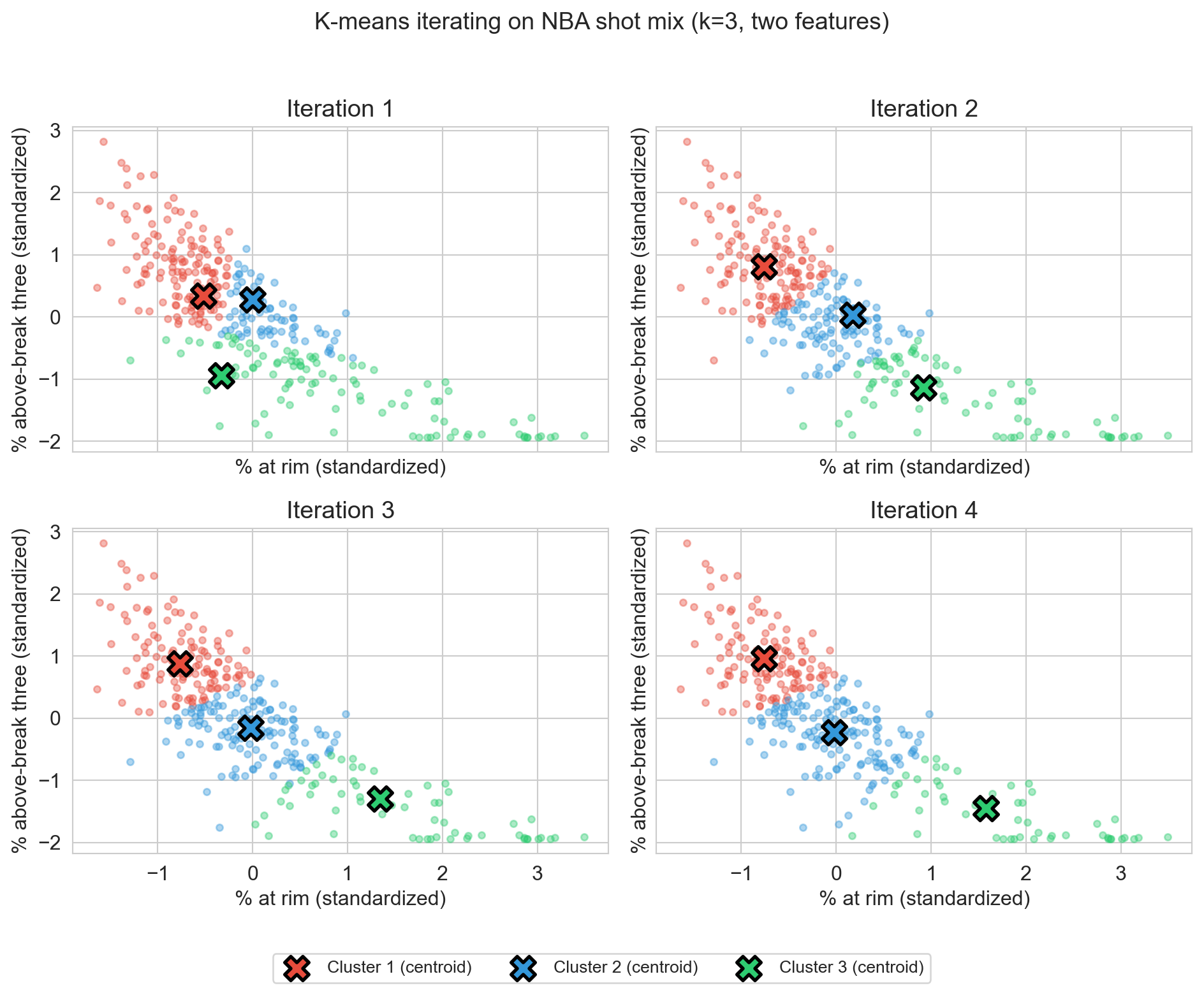
k=3, two features (rim share, above-break-3 share), four iterations
five archetypes

each panel = one archetype’s mean shot mix across the five zones
the archetypes spread across the floor
k-means didn’t see position labels at all, yet the midrange-masters cluster mixes a guard (Brunson), a wing (Edwards), and a forward (Durant).
what do the heuristics say?
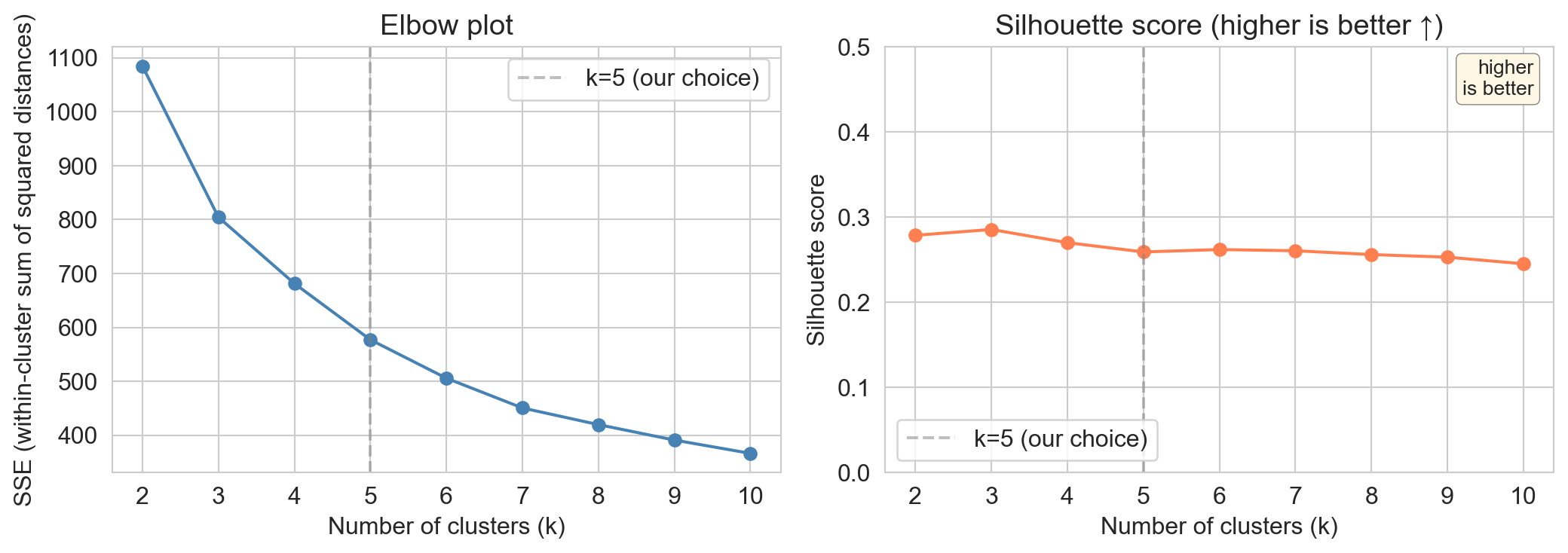
- elbow: gradual, no sharp bend
- silhouette: peaks at k=3 (k=2 a close second), then drifts down
- both rule out clearly bad k, neither picks k for you
silhouette, per player
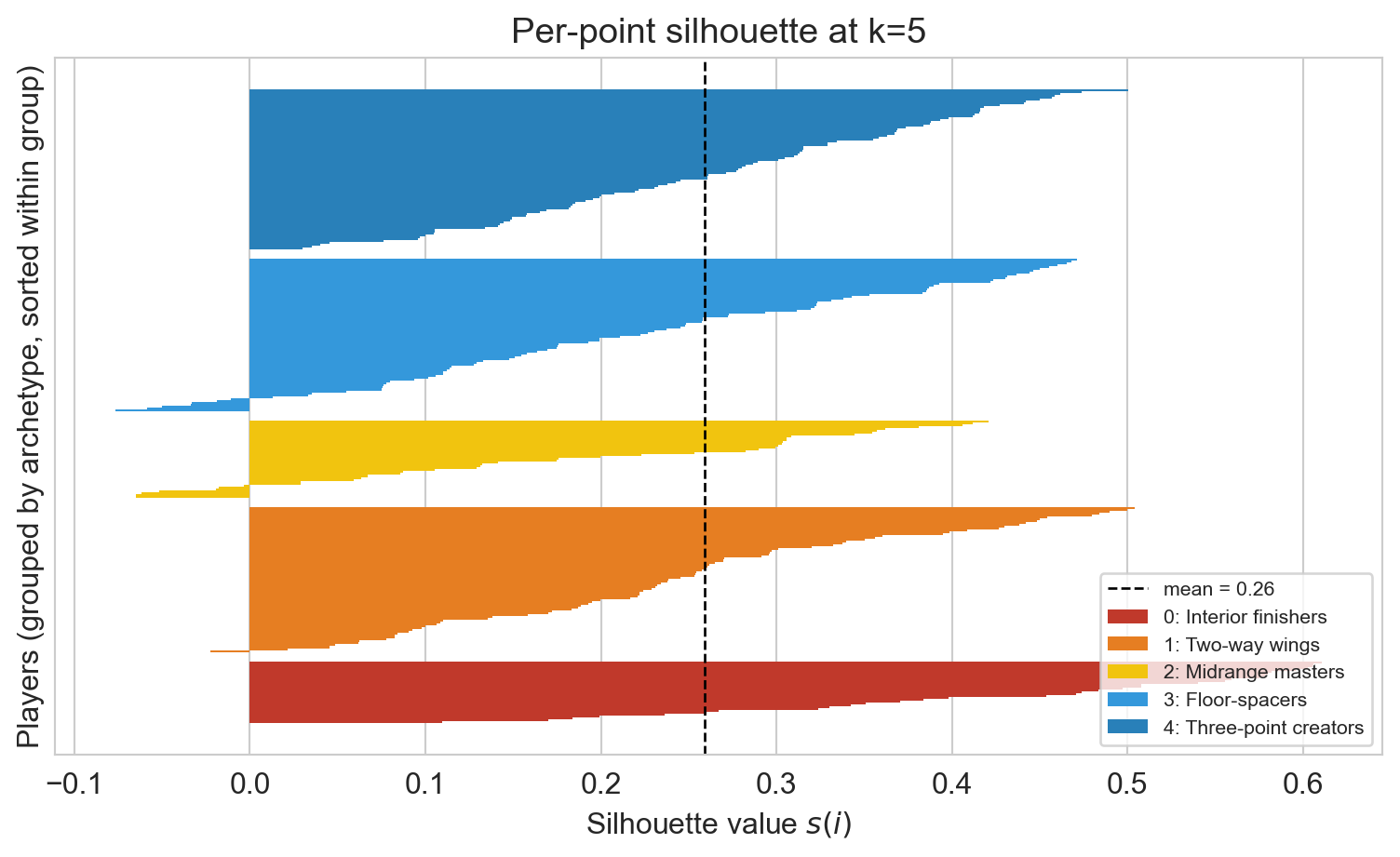
each bar = one player’s silhouette score, grouped by archetype
a tree of merges
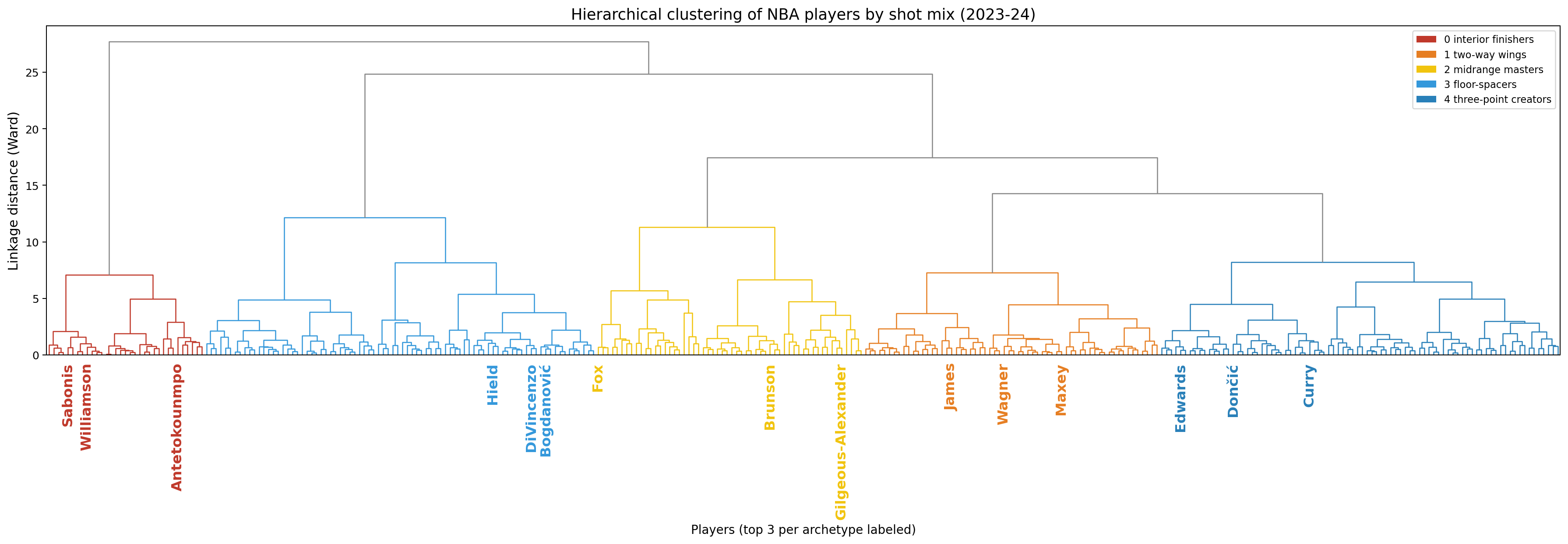
top 3 players by FGA in each archetype labeled. neighboring leaves play similarly.
- cut high → coarse partition (a few big groups)
- cut low → fine partition (many small groups)
- a second algorithm on the same data: how much does it agree with k-means?
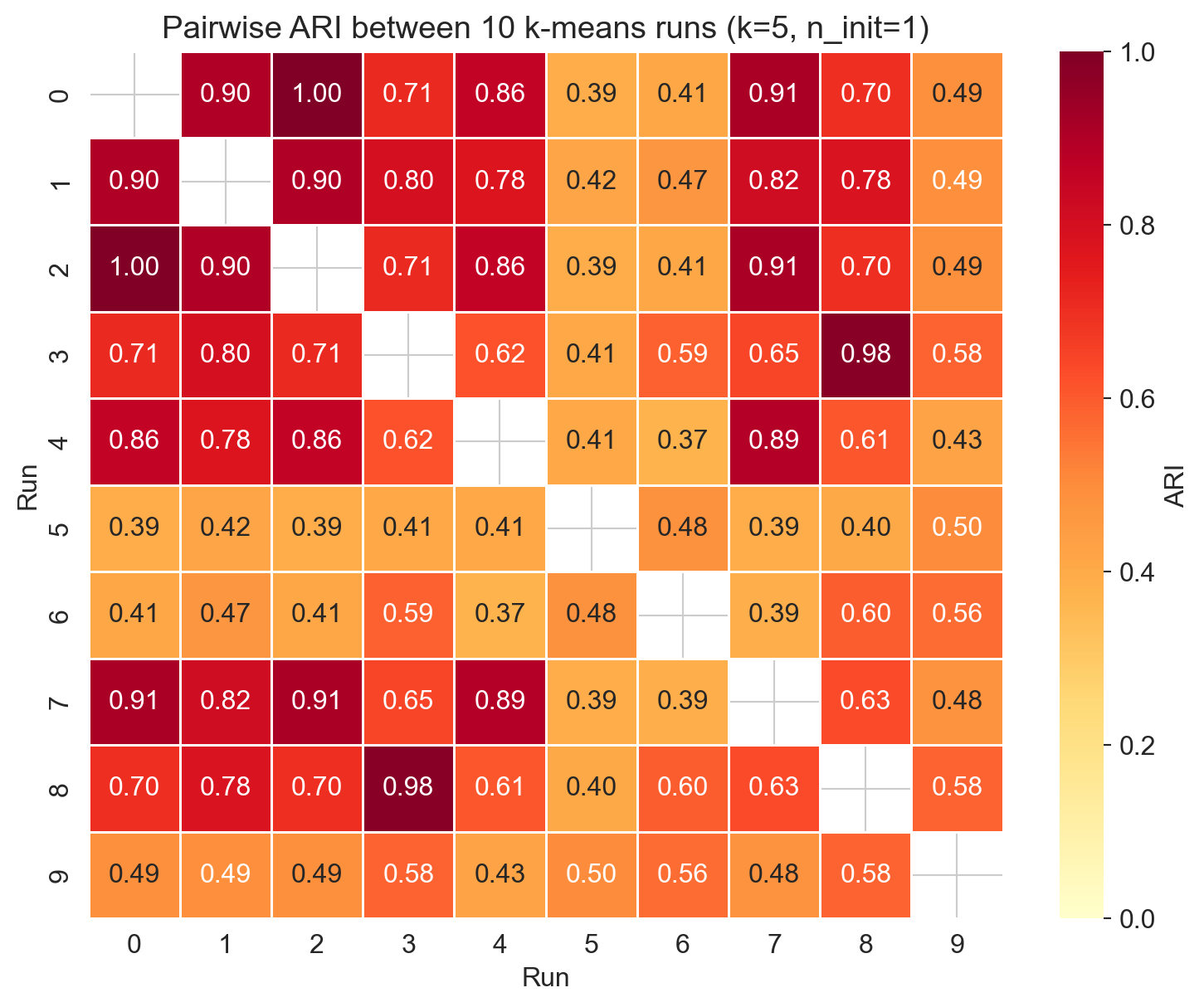
10 runs, pairwise ARI
- mean ARI = 0.62, range 0.37 – 1.00 across 45 pairs
- some pairs agree perfectly (ARI = 1); some find genuinely different partitions
- same data, same algorithm, same k: different clusters across runs
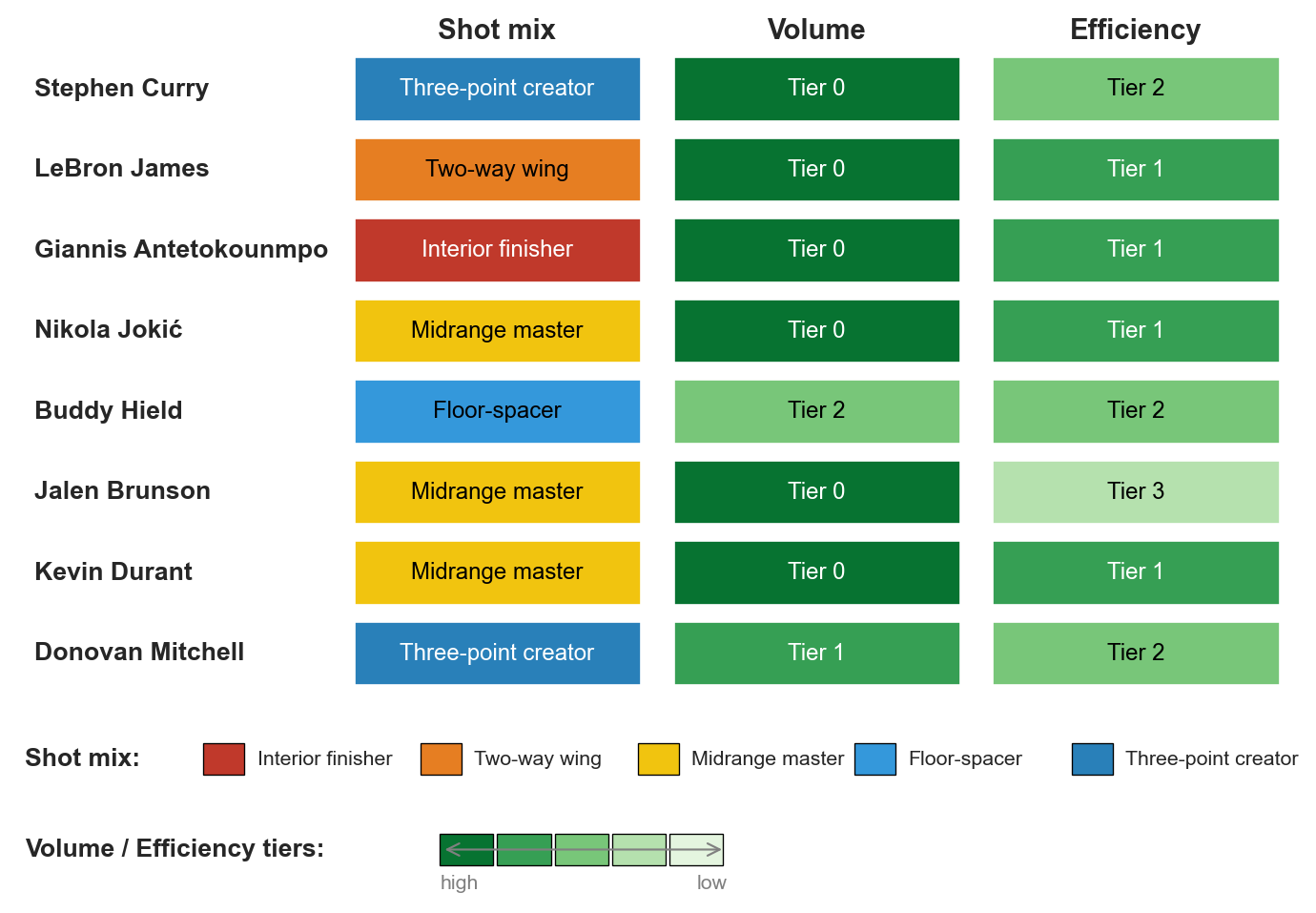
three stories, eight spotlight players
each row = one player labeled three ways. color encodes the tier.
clustering as the scaffolding of a cell atlas
- 100,605 mouse cells, 20 organs, no labels
- PCA + graph clustering → ~50 clusters
- each cluster annotated by its marker genes: decades of cell biology
- almost every named cell type came back out
- validation came from outside the algorithm

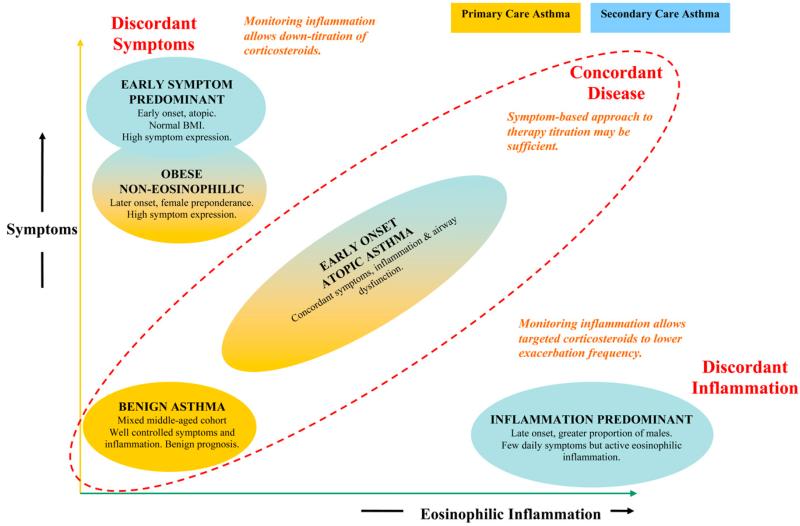
clusters that change which drug you should take
- 184 + 187 + 68 asthma patients, 8 clinical features
- hierarchical + k-means → 4 clusters
- one cluster is discordant: high inflammation, few symptoms
- RCT: treat by inflammation → exacerbations 3.53 → 0.38/yr (p = 0.002)
- cluster membership predicted which treatment helped
beautiful clusters, no replication
- Drysdale 2017, Nature Medicine. n = 1,188 depressed patients
- CCA + hierarchical → 4 depression biotypes, 82–93% accuracy
- Dinga 2019 replication, n = 187: permutation p of canonical correlations 0.64, 0.99
- cluster p = 0.45. cross-validated correlations ~0
- noise made visible by an under-regularized projection
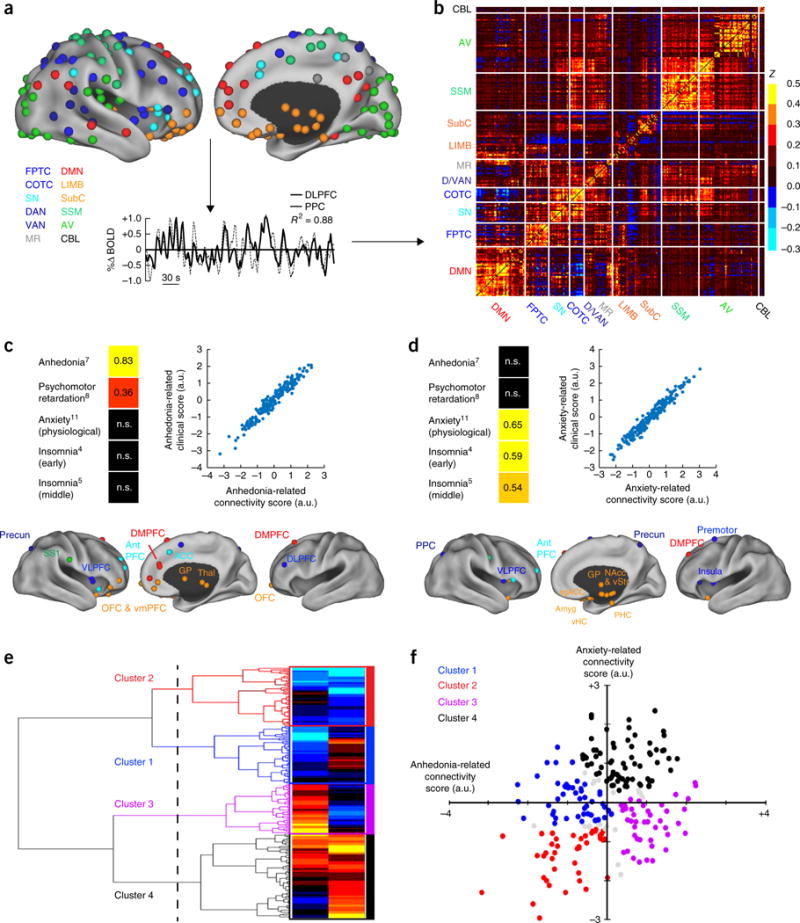
Drysdale et al., Nat. Med. 2017, Fig. 1; Dinga et al., NeuroImage: Clinical 2019
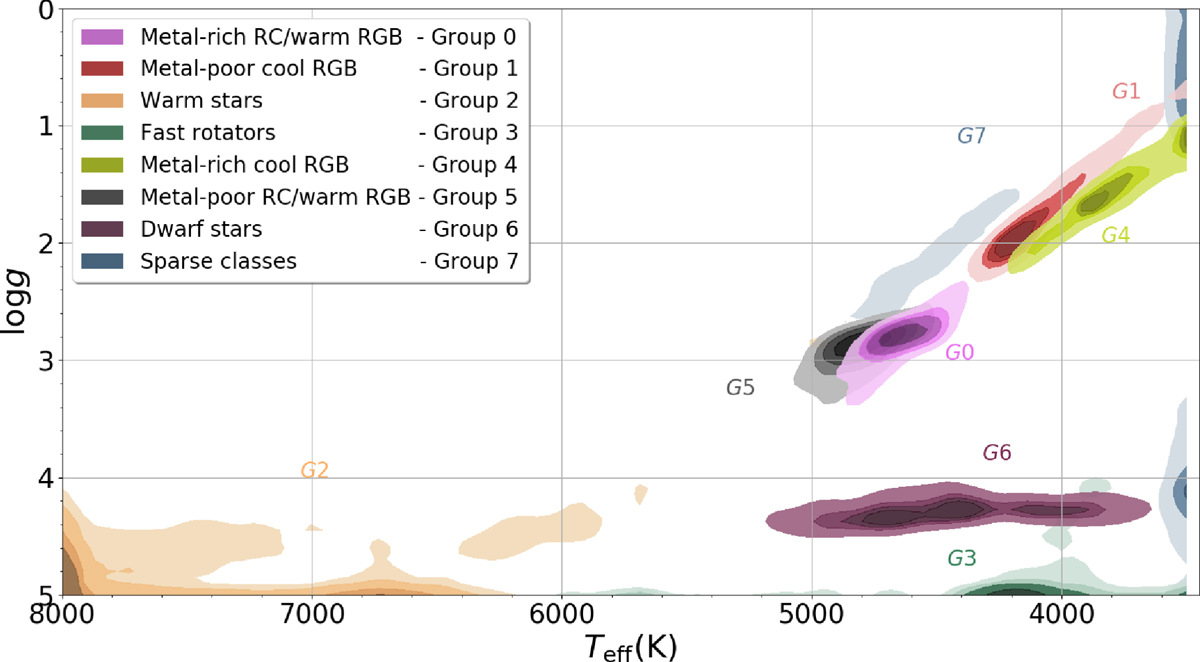
same lesson, even in physics
- APOGEE survey. 153,847 stellar spectra. k-means in raw flux
- some real populations recover: dwarfs vs. giants, bulge vs. halo
- authors: “a discrete classification in flux space does not result in a neat organisation in the parameters space”
- sensitive to initialization too
- populations real, features wrong: flux distance ≠ physics distance
feedback

what worked? what didn’t? what’s still confusing?