Lecture 14: PCA and Dimensionality Reduction
MSE 125 — Applied Statistics
Wednesday, May 13, 2026
the brief
risk analyst, $5B asset manager
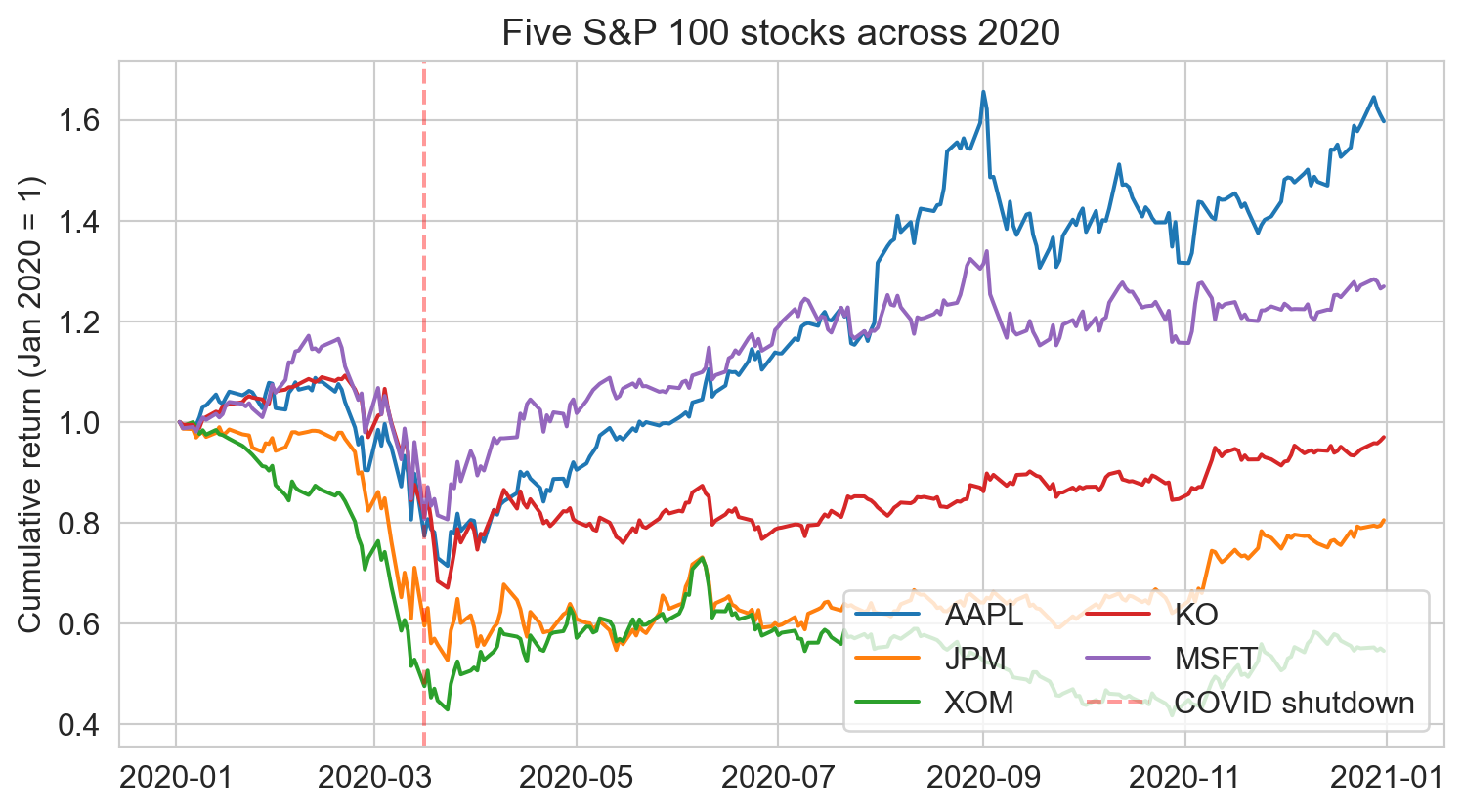
your book: S&P 100 stocks.
last March: every name crashed together
CIO asks: what risk are we really exposed to?
Pearson 1901: same picture, drawn before computers
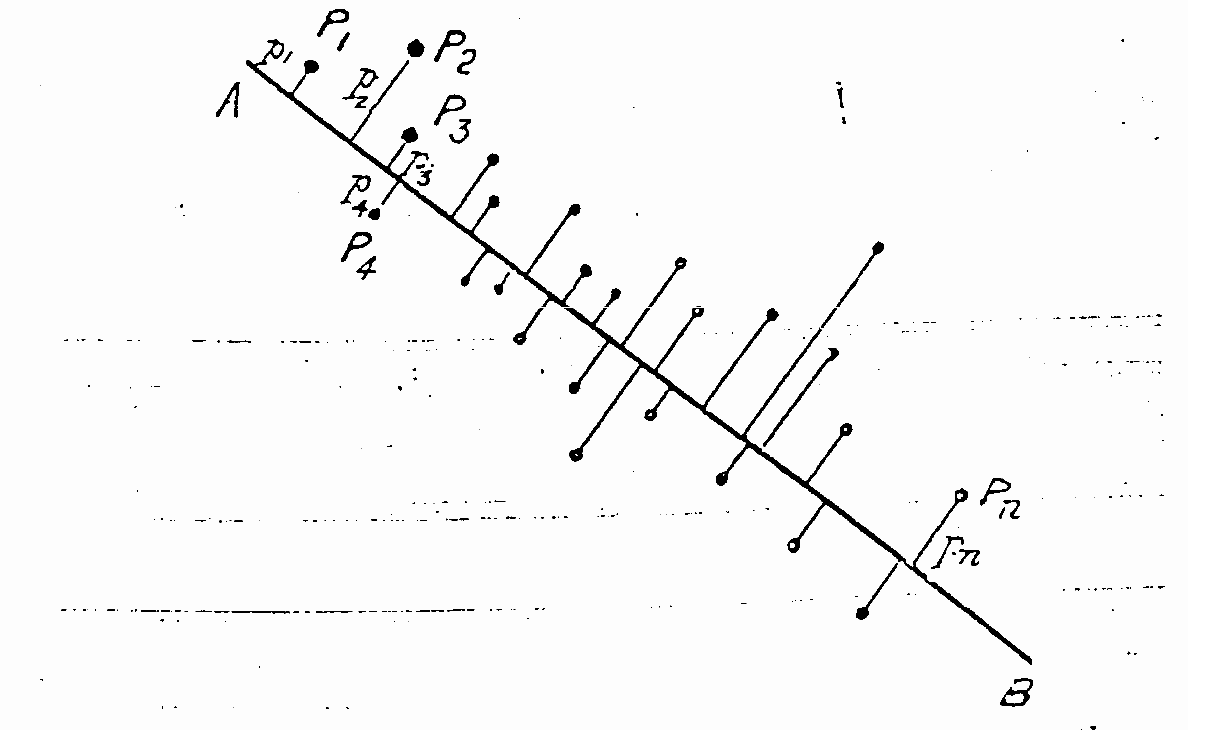
Pearson, Phil. Mag. 1901
given a cloud of points, what line minimizes the sum of squared perpendicular distances from points to the line?
Pearson answered this in any number of dimensions, with just elementary geometry
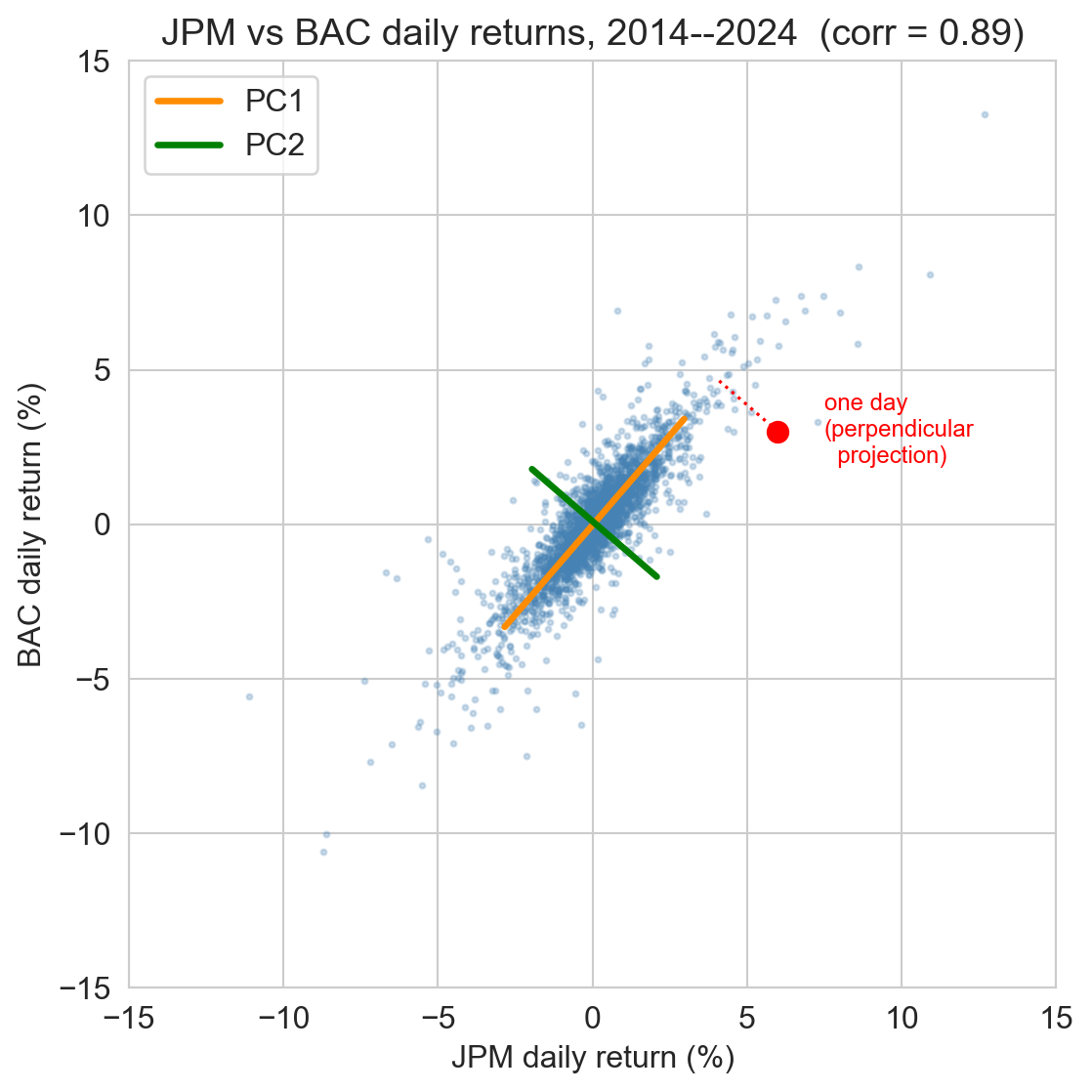
same picture, real data: JPMorgan vs Bank of America
without standardization: high-vol stocks dominate
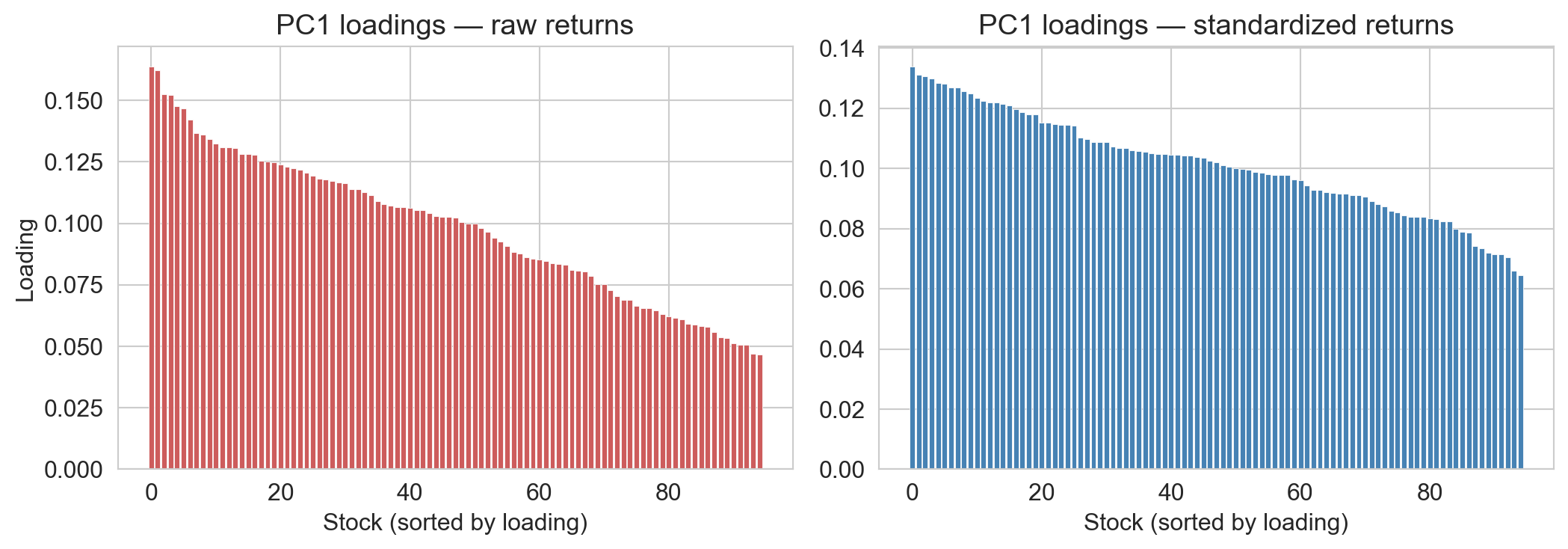
top 5 by |PC1 loading|
| raw | standardized | ||
|---|---|---|---|
| AMD | 0.164 | BLK | 0.134 |
| NVDA | 0.162 | HON | 0.131 |
| COF | 0.153 | MS | 0.131 |
| TSLA | 0.152 | JPM | 0.130 |
| BA | 0.148 | C | 0.128 |
→ raw: semis, EV, aerospace. the loud names, top 5 hold ~12%
→ standardized: financials. the most market-correlated, top 5 hold ~8.5% (baseline 5.3%)
the scree plot: variance per PC
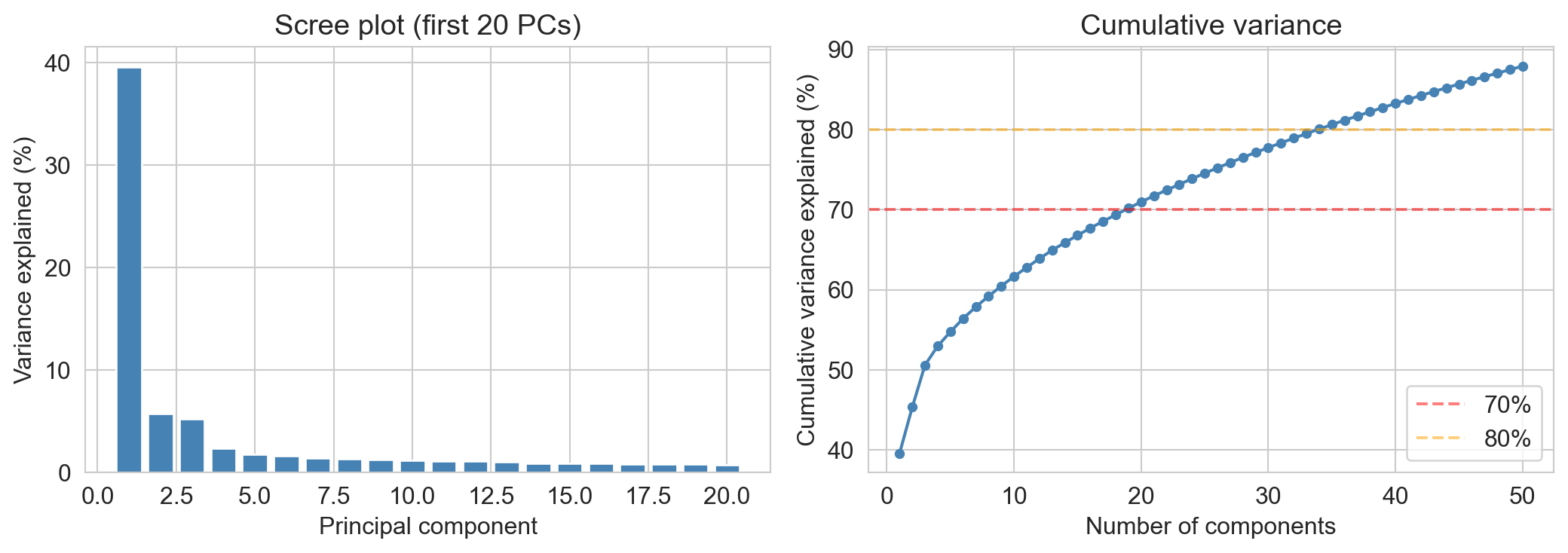
- PC1 alone: ~40% of variance
- 70% needs ~20 PCs; 80% needs ~35
- one big factor + a long flat tail: typical of equity returns
interpret PC1: the market factor
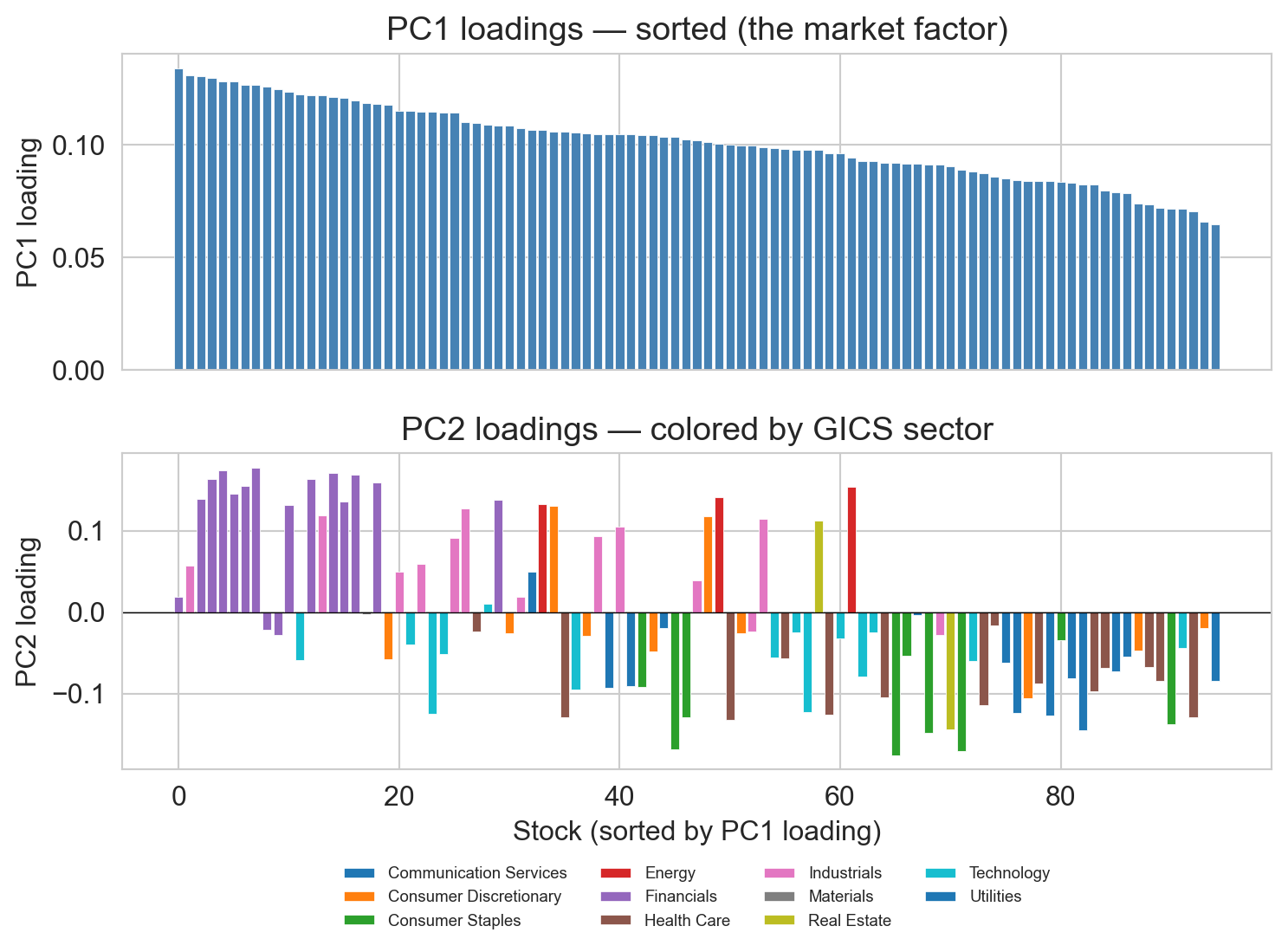
top: every stock loads positively → PC1 is the common up-down move
bottom (PC2, sectors): financials + energy on top; staples + utilities on bottom
→ PC2 = cyclicals vs defensives
interpret PC3: growth vs yield
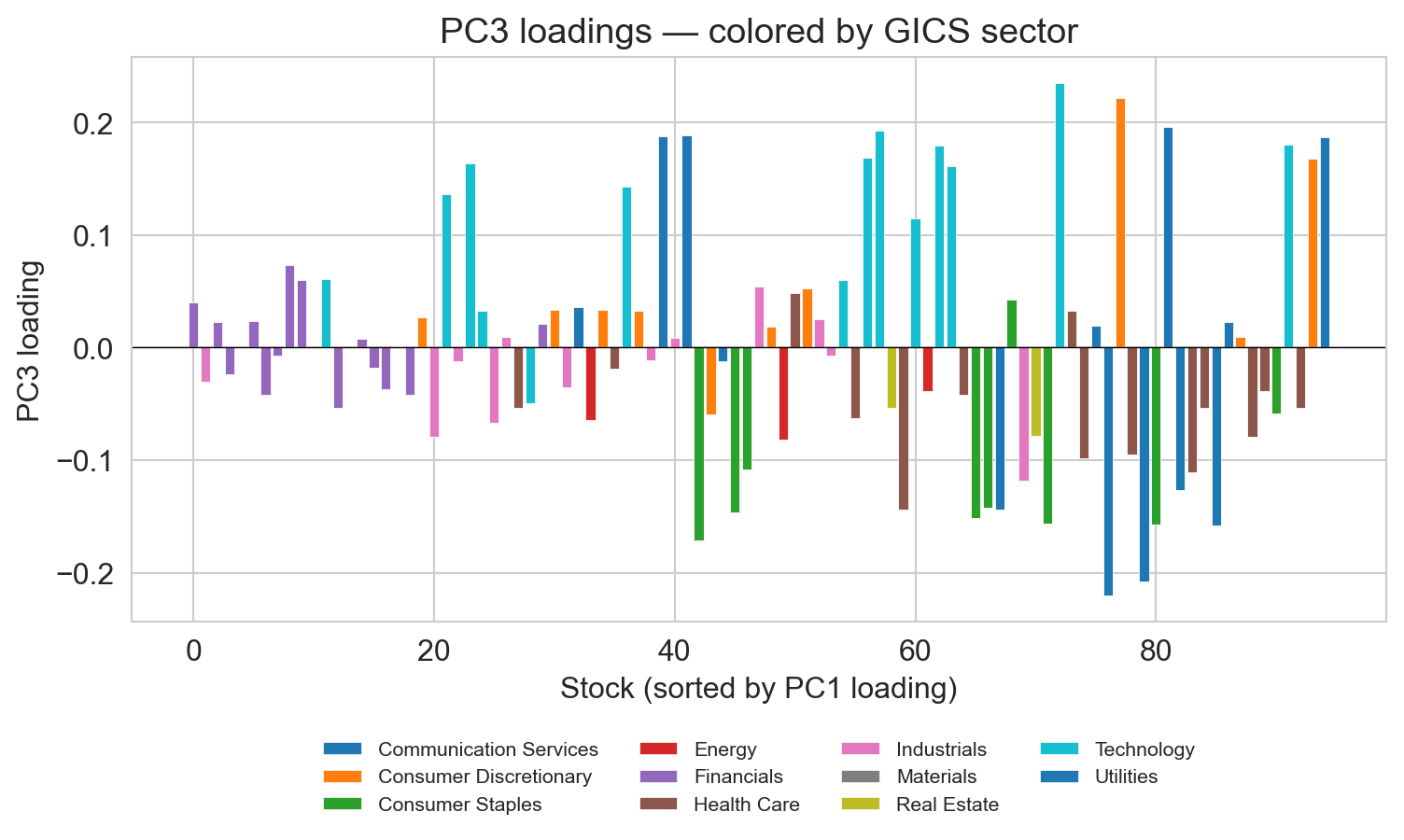
positive: NVDA, AMZN, META, GOOGL, ADBE → growth tech
negative: utilities (DUK, SO), staples (KO), high-dividend telecom (VZ) → yield
by PC5 or PC6, the economic story runs out
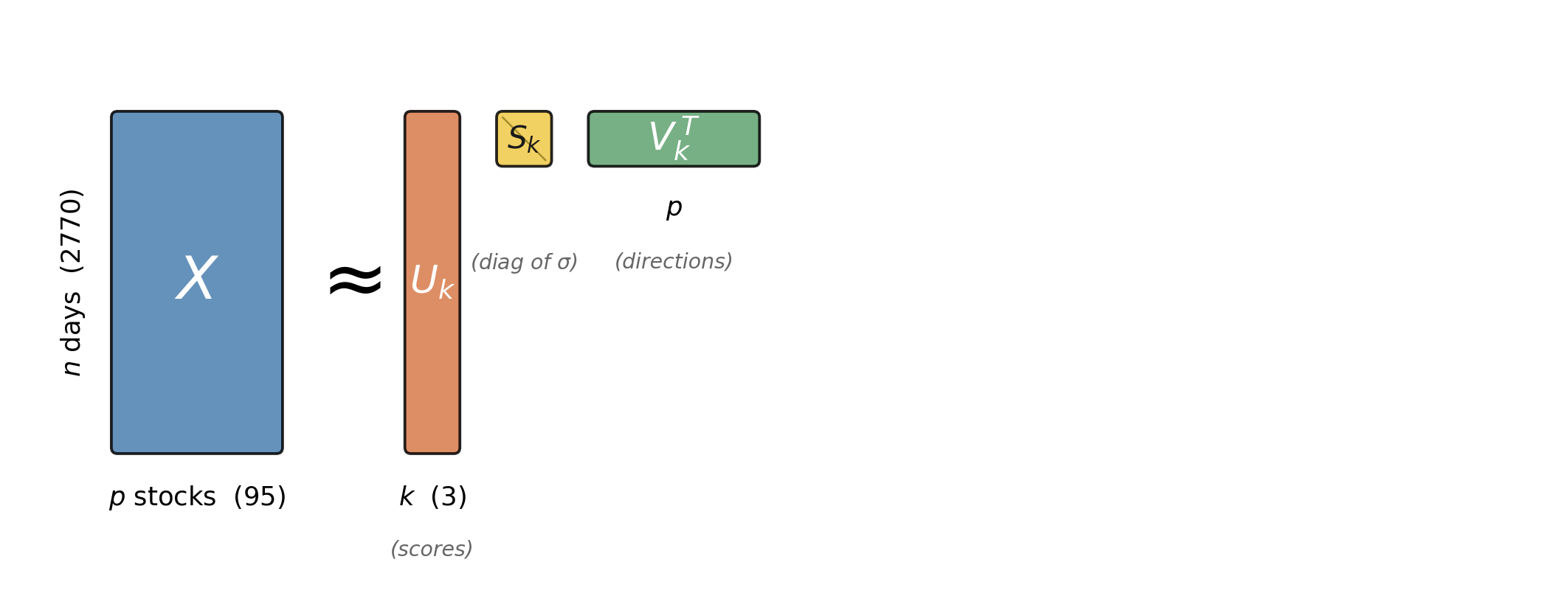
the math: how do we solve it?
data matrix X \in \mathbb{R}^{n \times p}, where row i = x_i
- 2 stocks (earlier): eigendecomposed the 2 \times 2 covariance
- general X: truncated SVD X \approx U_k S_k V_k^T (works directly on X; no covariance to form)
the result: variance vs k
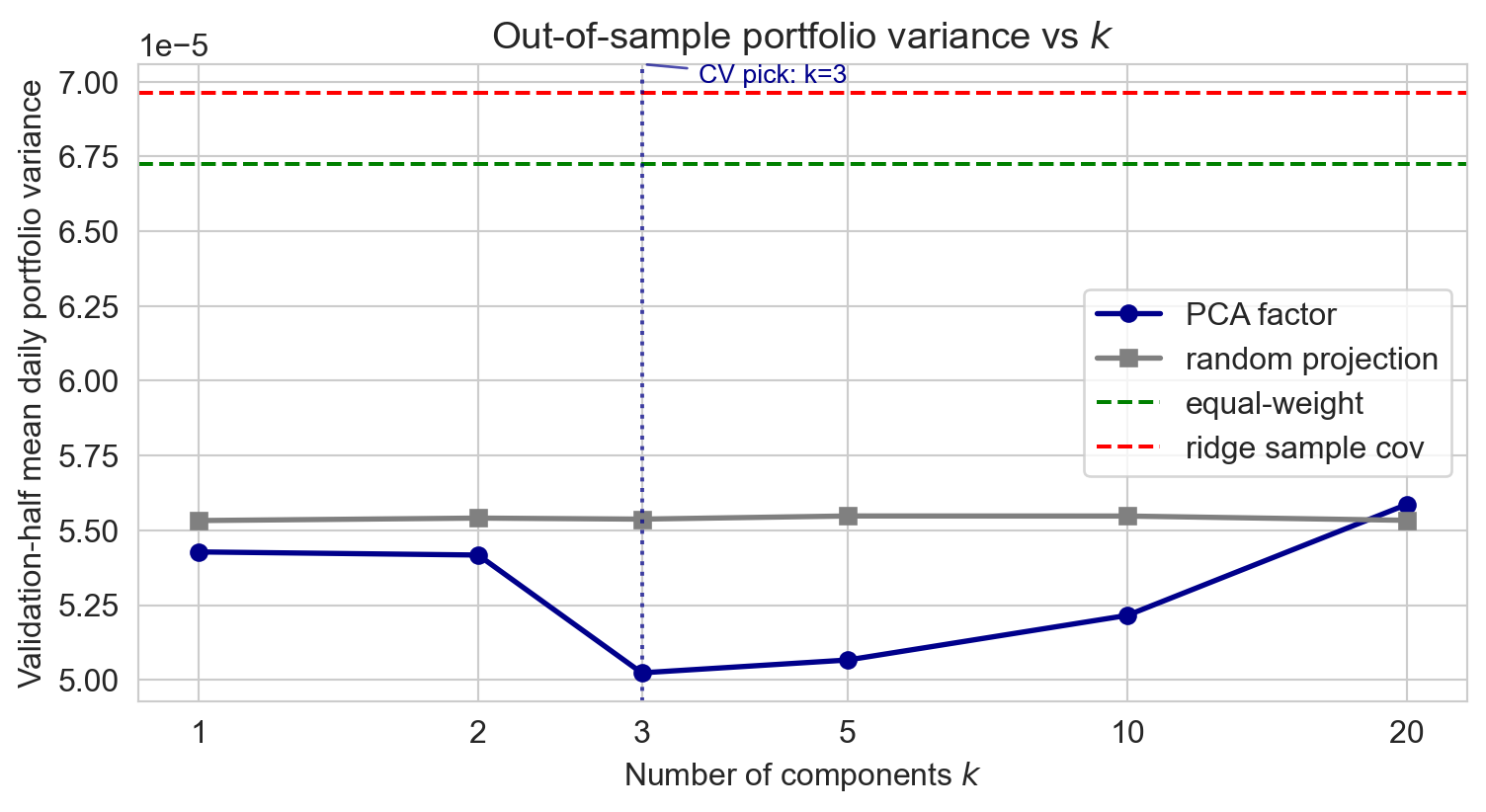
- PCA factor (blue) drops fast 1→3, flat-ish 3→10, rises past 10
- CV picks k = 3: well below scree’s “elbow at 1”
- random projection (gray) lies above PCA throughout: variance-aligned directions matter
the result: cumulative variance over time
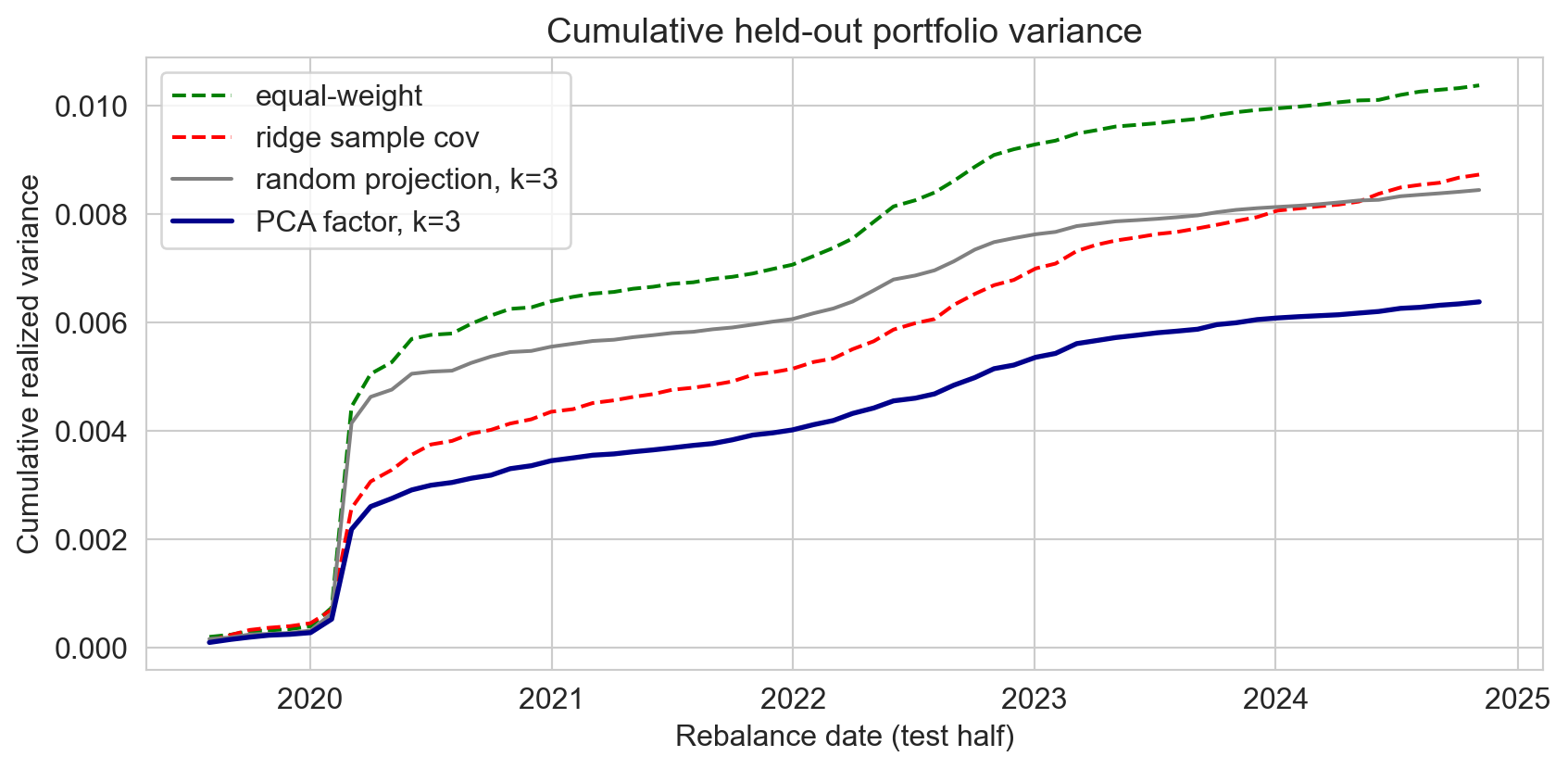
PCA factor portfolio sits lowest the entire test period
every method jumps at COVID; PCA’s jump is smallest
cautionary tale: genes mirror geography
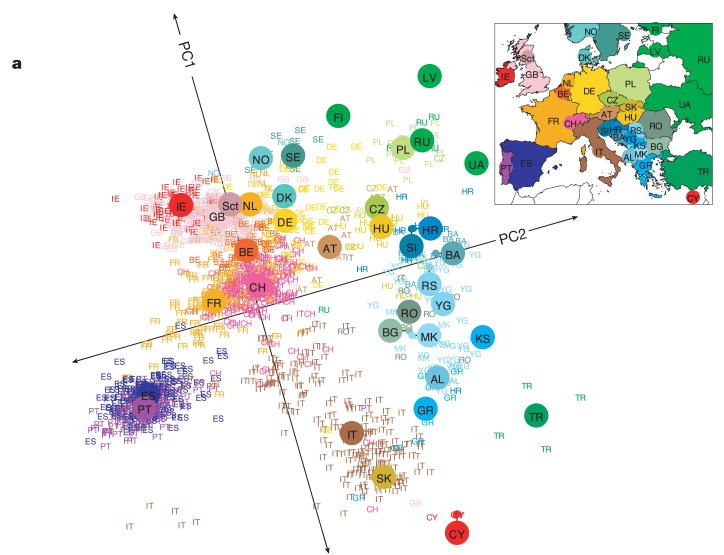
197K SNPs, 1,387 Europeans
no geographic info given to the algorithm
→ it drew a map of Europe (r^2 \approx 0.7)
. . .
→ math result: PCA on spatial data with distance-decaying similarity generically produces these patterns
→ recovering an obvious pattern is not evidence of hidden structure
Novembre 2008; Novembre & Stephens 2008
feedback

what worked? what didn’t? what’s still confusing?