Lecture 13: Decision Trees and Random Forests
MSE 125 — Applied Statistics
Monday, May 11, 2026
the brief
Airbnb host, NYC
goal: develop a pricing tool to help hosts set competitive nightly rates
ch 5: a reasonable R^2, but you picked the interactions, polynomial degree, and neighborhood encodings by hand
keep hand-engineering, or use a model that splits on its own?
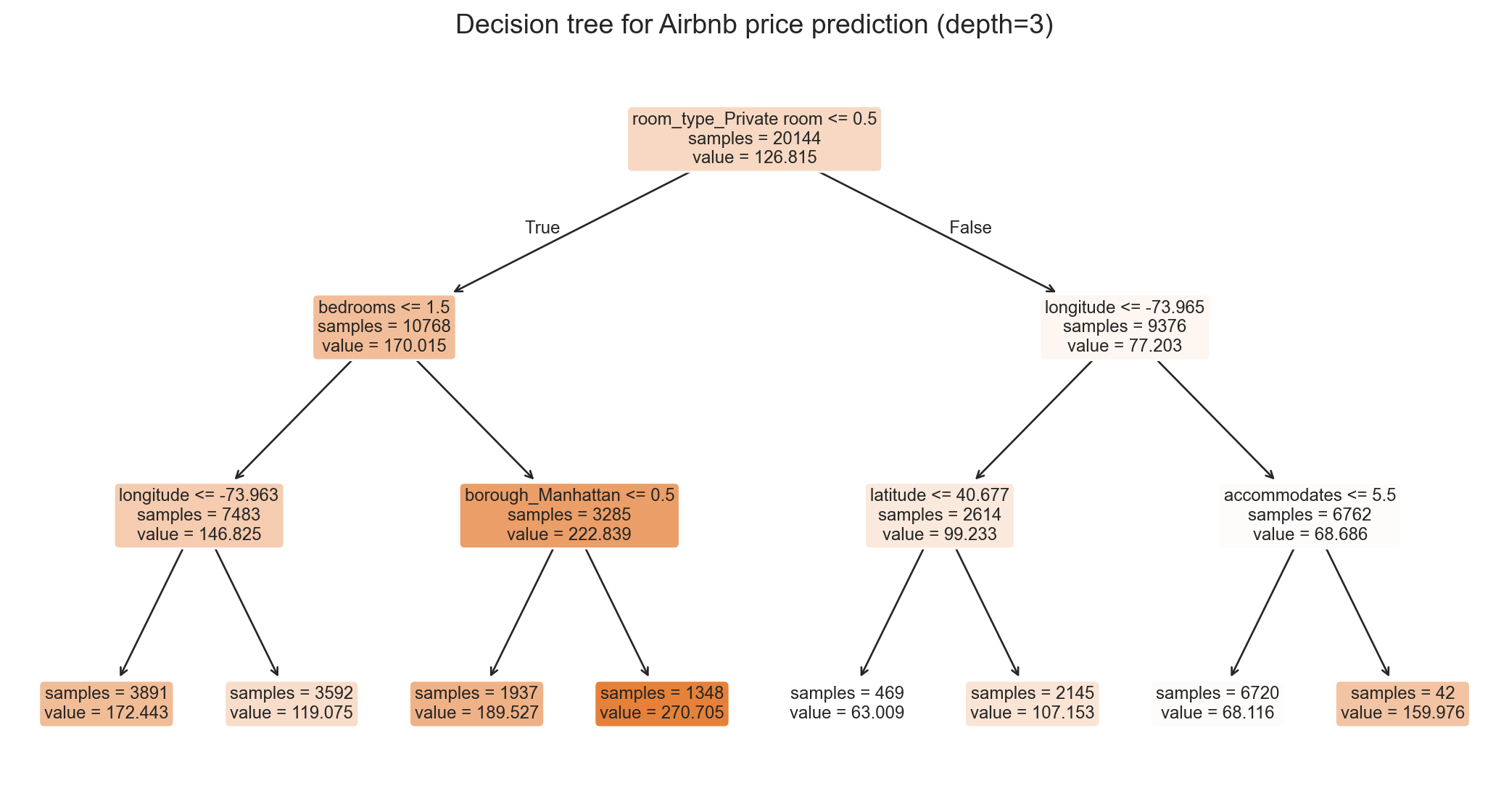
decision tree, in pictures
each leaf reports a predicted price + sample count
tree vocabulary
decision tree
recursive if/then splits on one feature at a time
- leaf: node with no children; carries a prediction
- internal node: any non-leaf node; asks a yes/no question, routes to a child
- root: the single internal node at the top
- depth: longest root-to-leaf path
max_depth: sklearn knob that limits depth
greedy partitioning, step by step
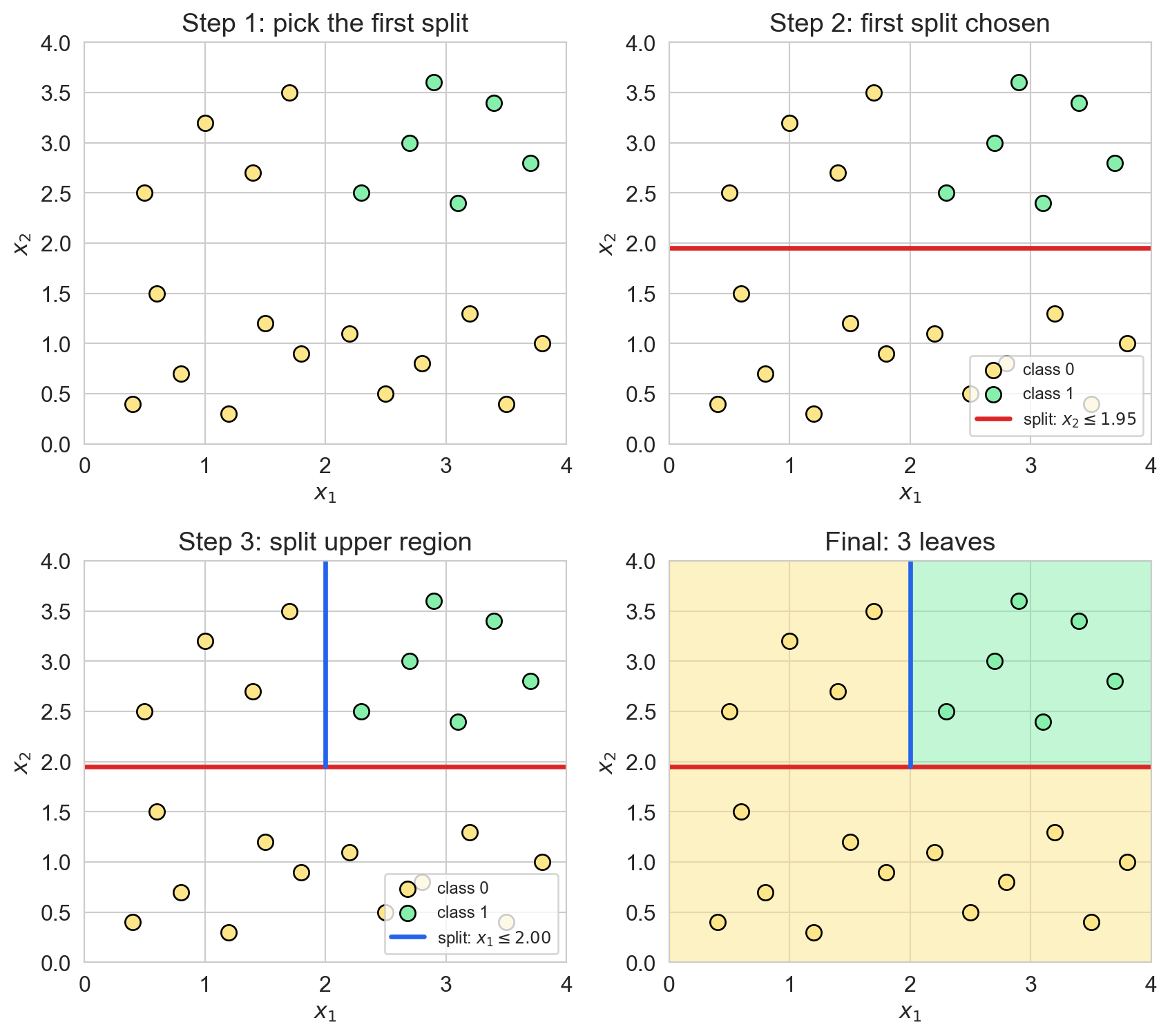
- greedy: best split now, never reconsidered
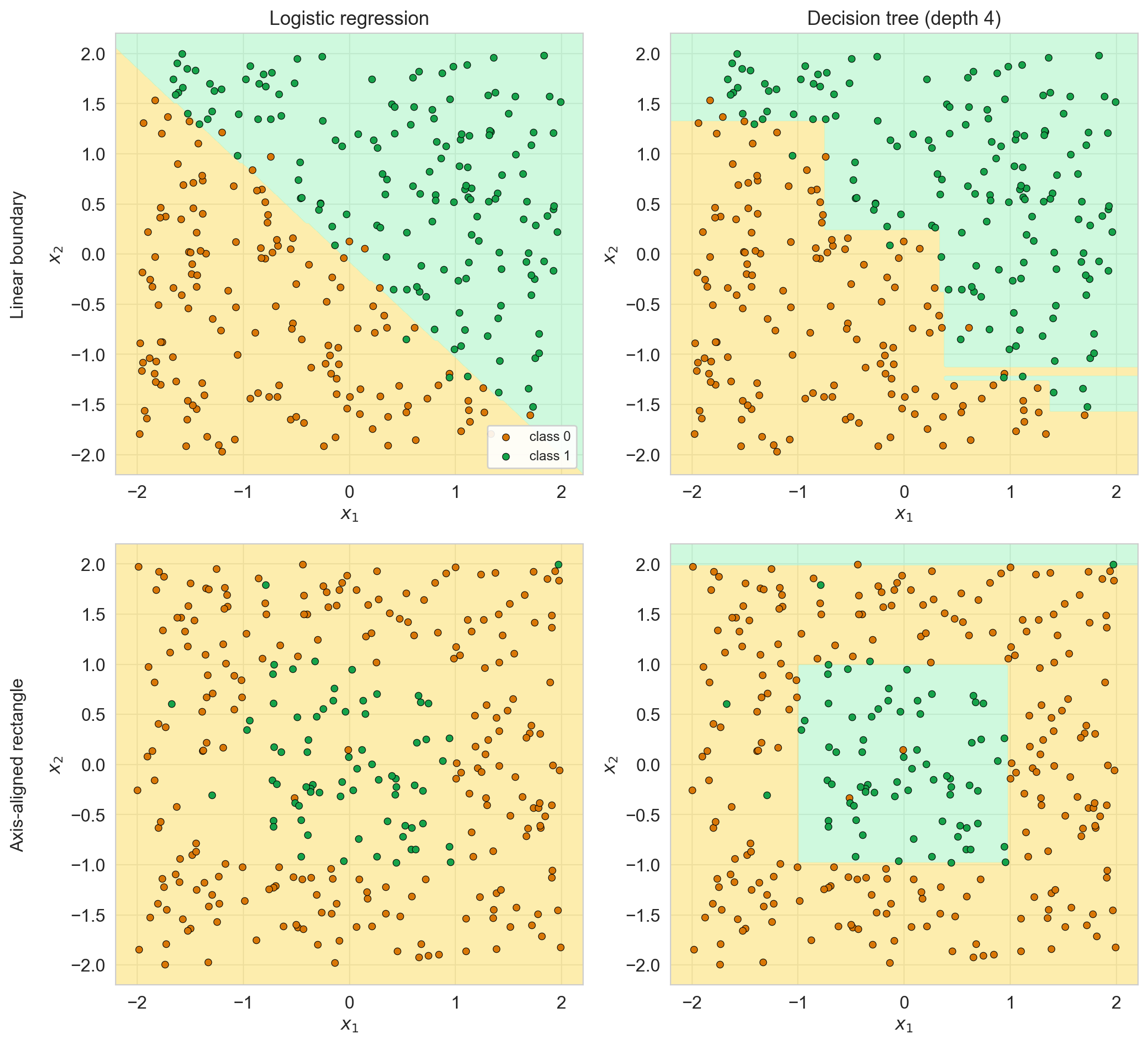
- axis-aligned: every cut parallel to an axis; a diagonal becomes a staircase
a single tree overfits
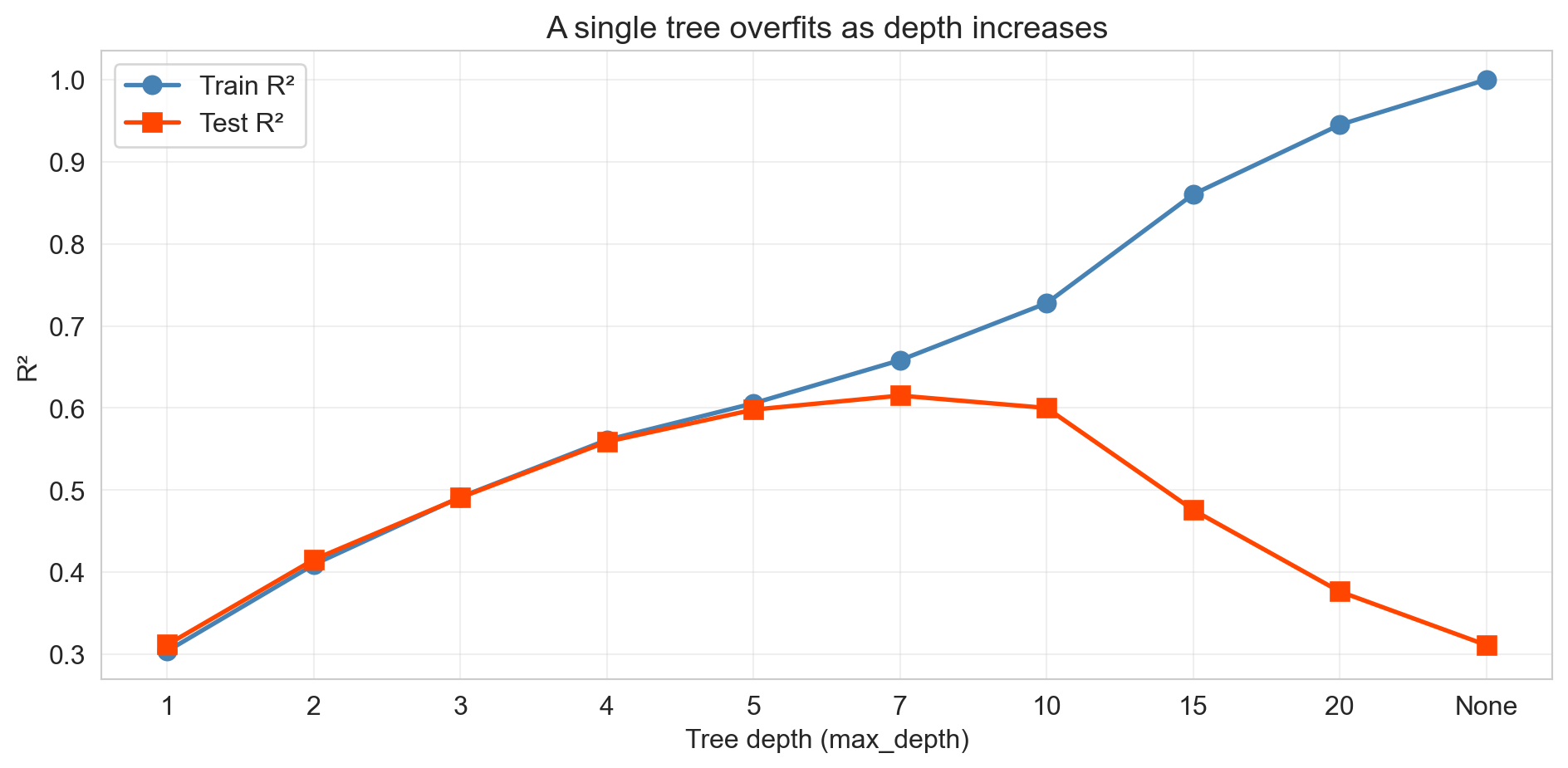
- shallow: underfits, high bias
- deep: memorizes training rows, high variance
- test R^2 peaks near depth 7, then collapses
shallow vs. deep, on a 2D slice
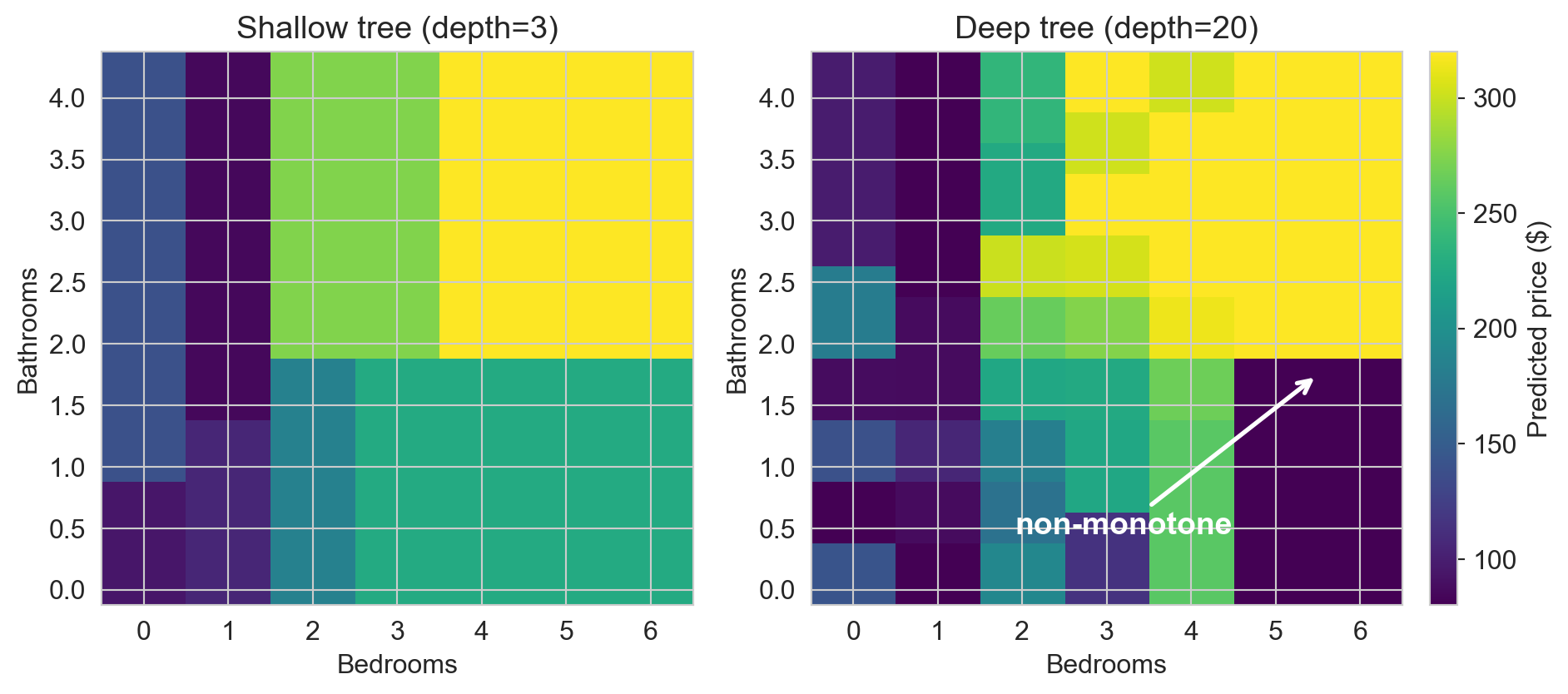
deep tree’s quilt shows memorization: adding a bedroom can lower the prediction
CV picks the depth
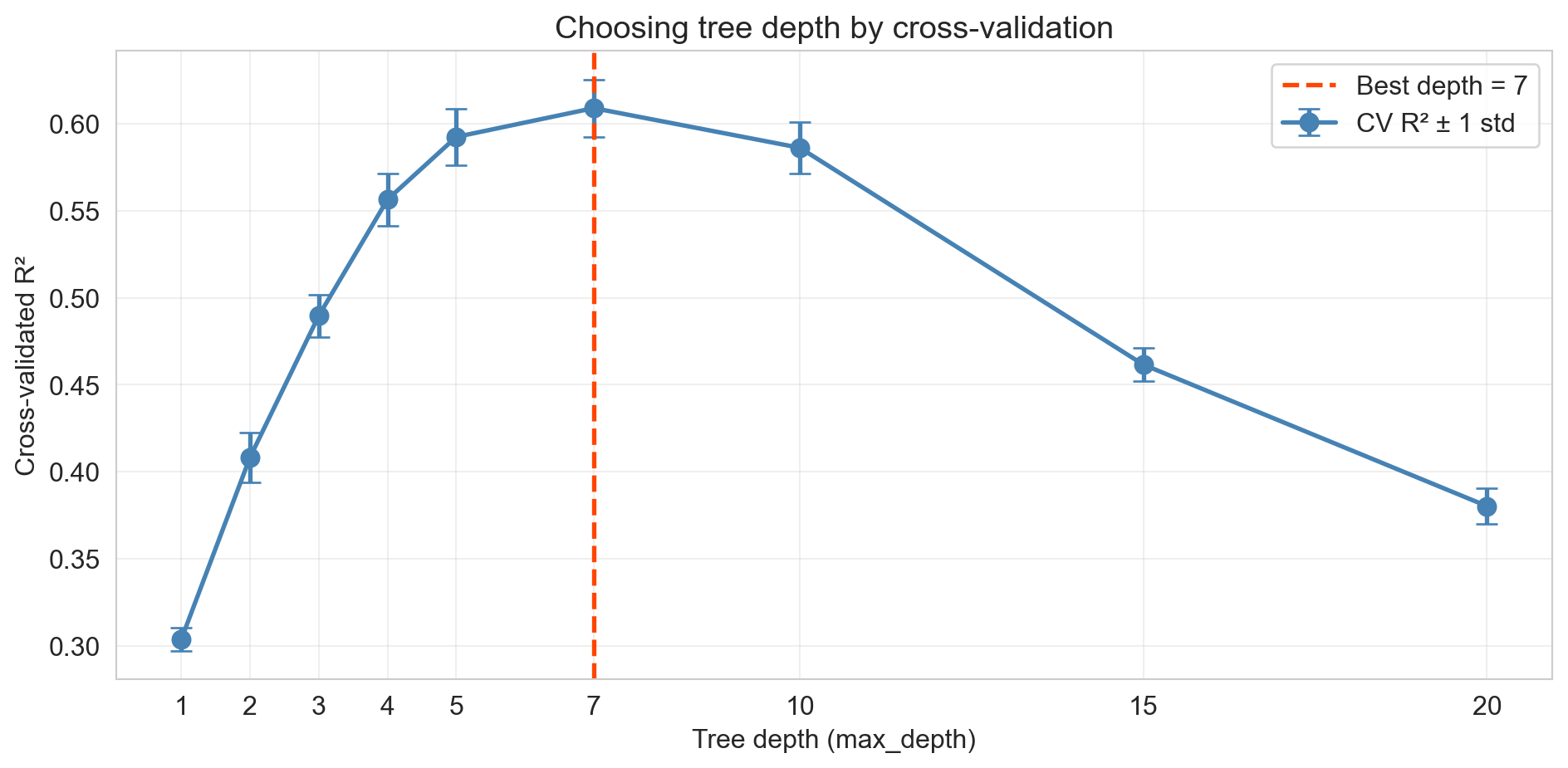
same recipe used for lasso \alpha, polynomial degree, k in kNN
the random forest, briefly
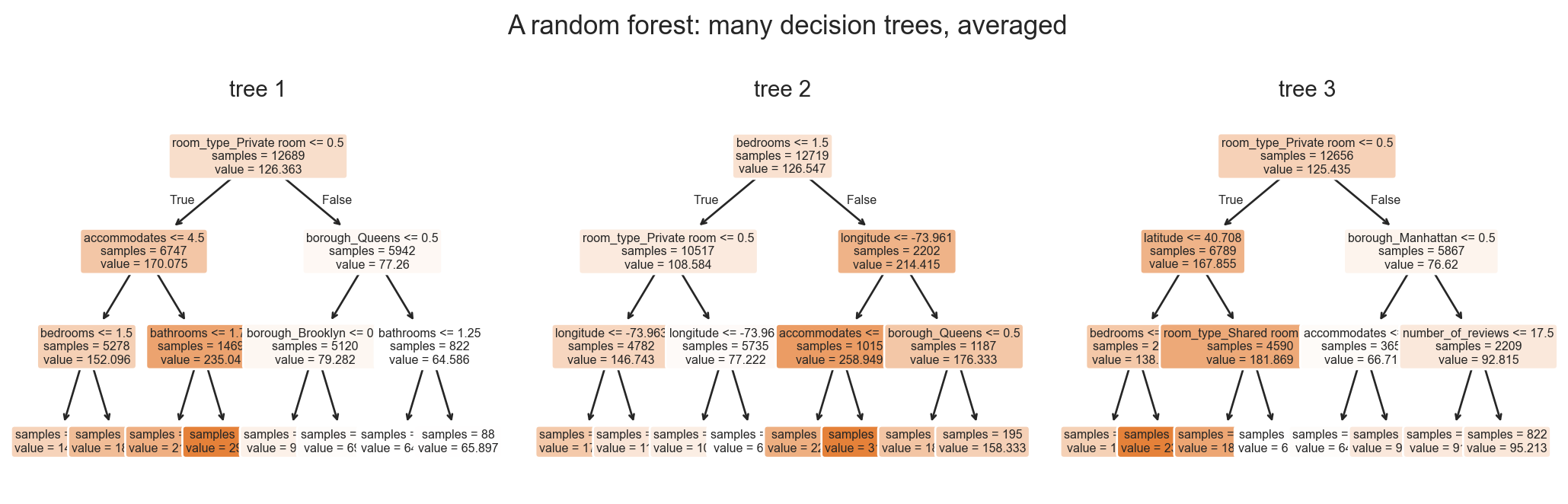
random forest
ensemble of deep trees, each trained on a bootstrap sample of rows, considering only a random subset of features at each split. predictions are averaged (regression) or voted (classification).
- bagging: each tree sees different rows
- feature subsampling: each split considers different features
- trees memorize different noise → averaging shrinks variance
bootstrap samples in pictures
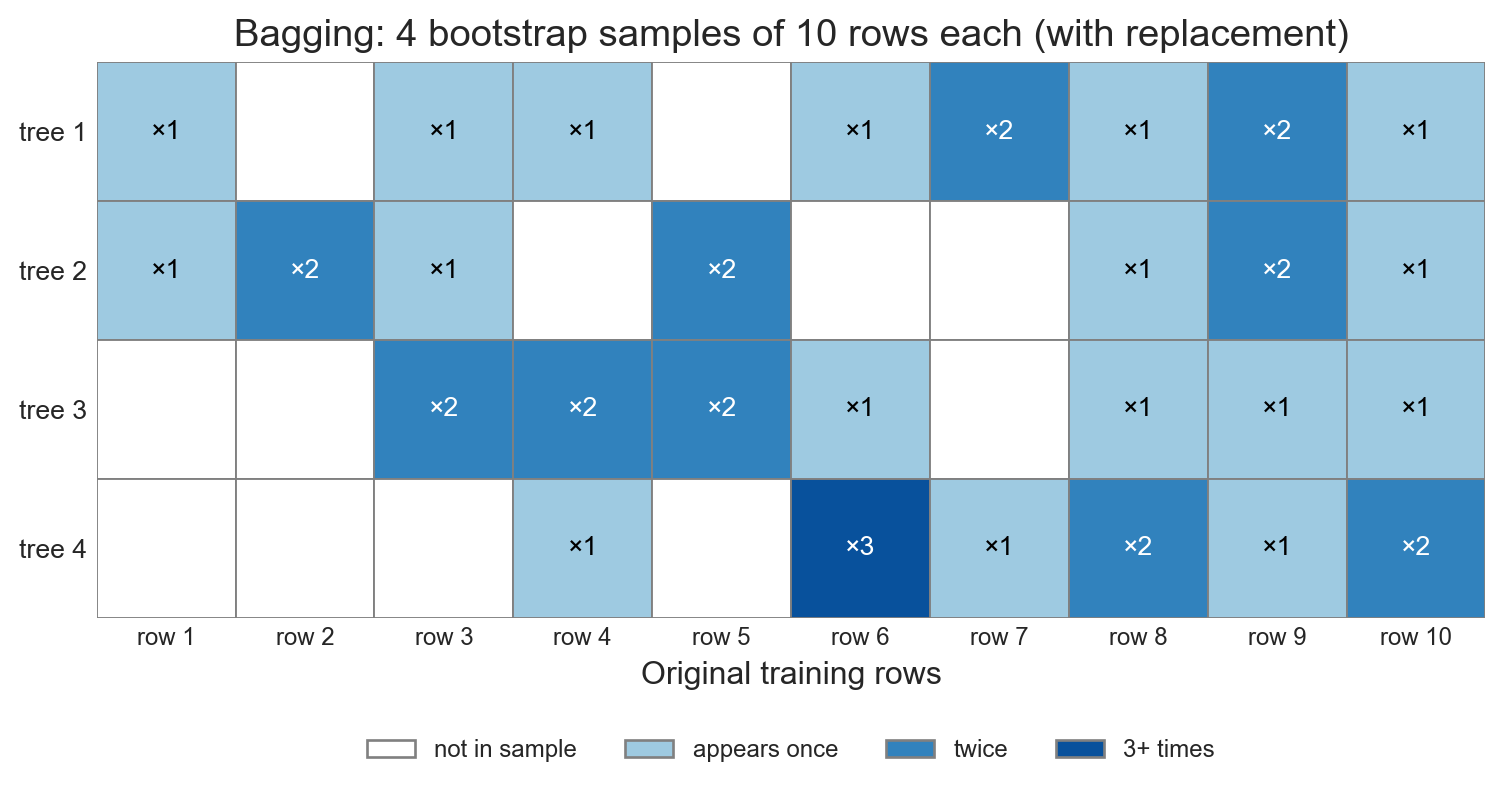
- each tree sees a different subset of rows
- some rows appear multiple times, some not at all
- skipped rows (\approx 37%) → out-of-bag (OOB) free validation
bootstrapped trees vs. their average
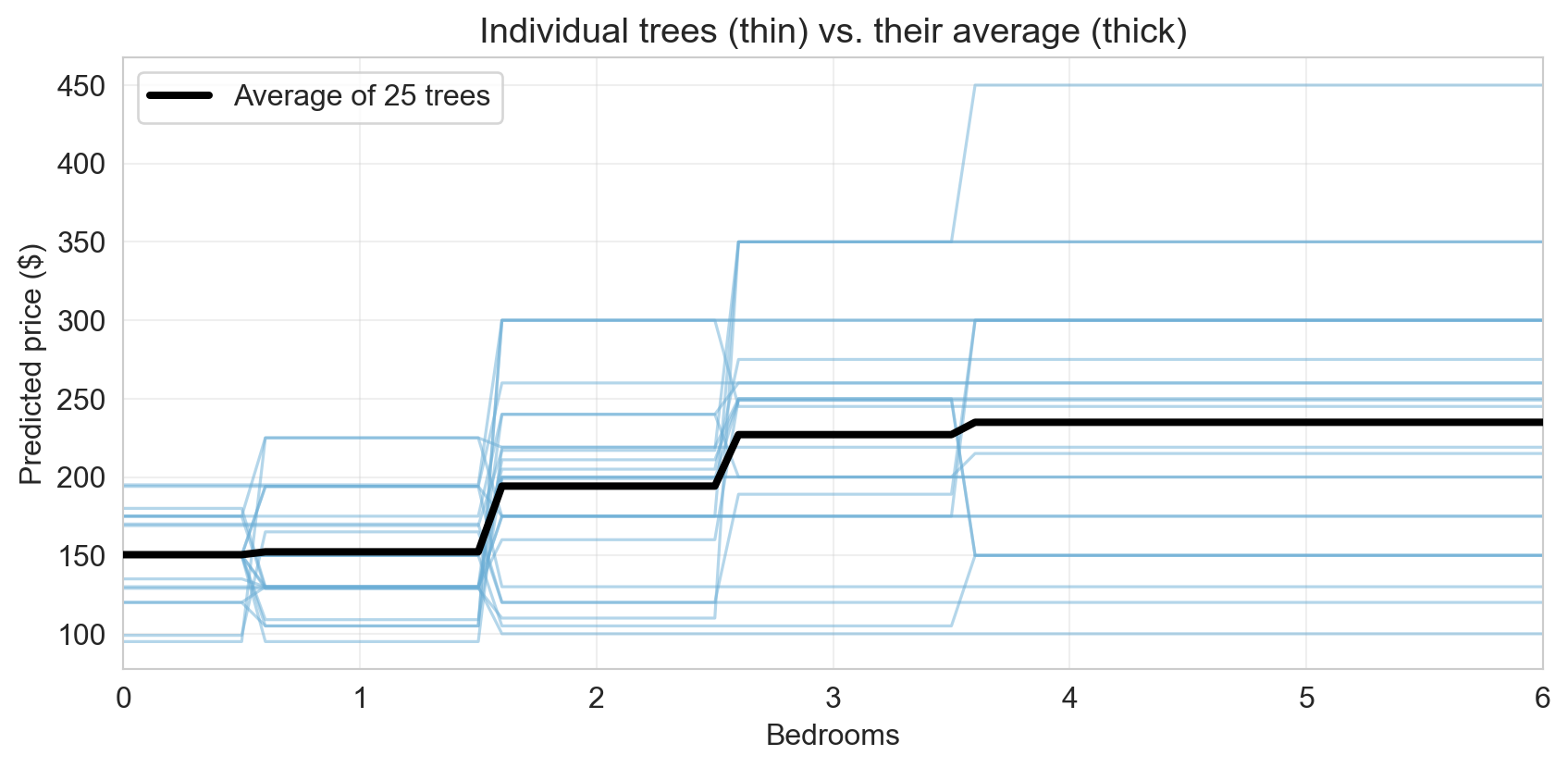
- thin blue: 25 deep trees, each fit on its own bootstrap sample
- thick black: the average prediction
- where individual trees disagree, disagreements partly cancel
variance shrinks with B
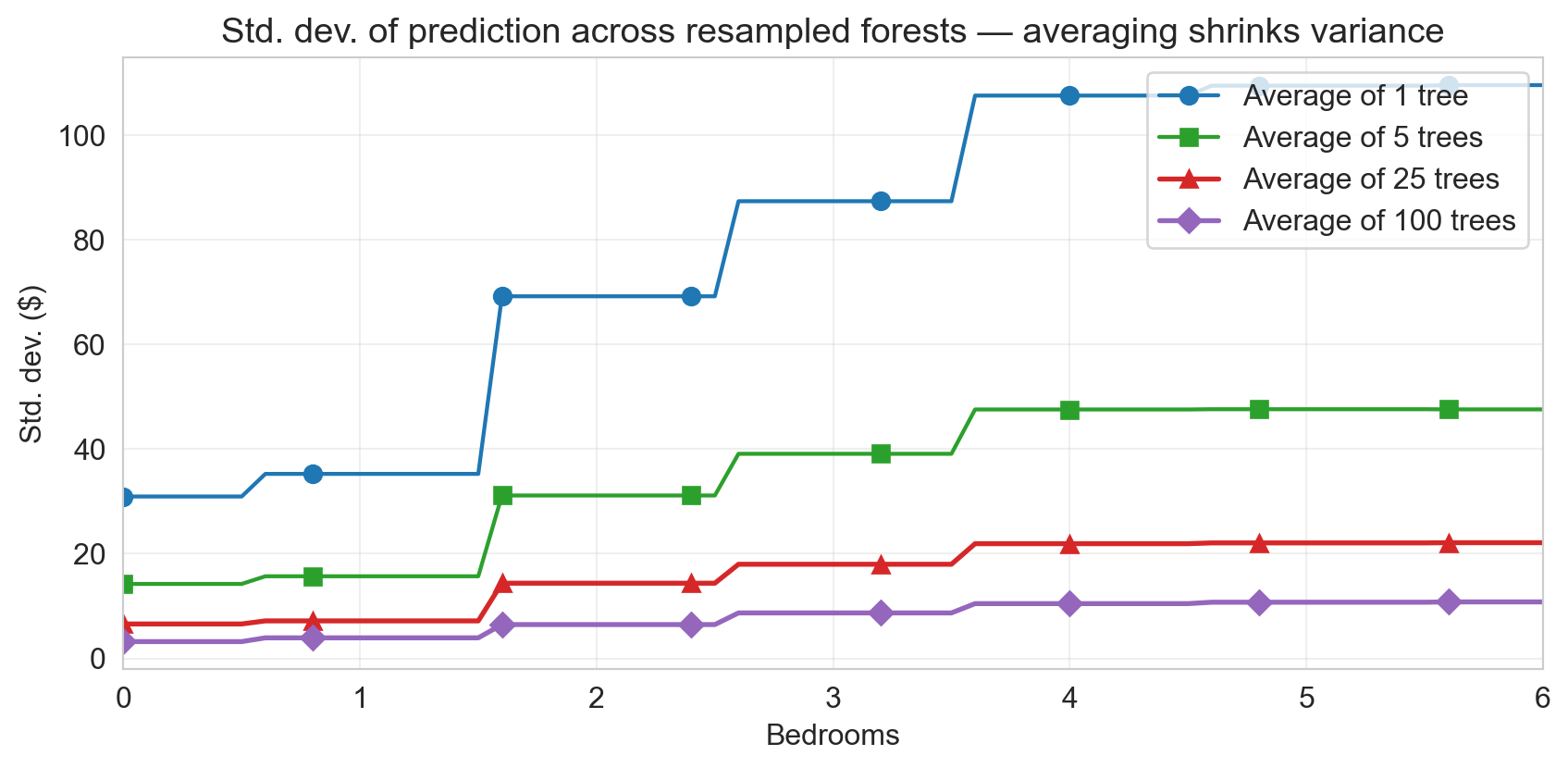
- each 4\times more trees → half the spread
- curves bend toward a floor
more trees rarely hurt
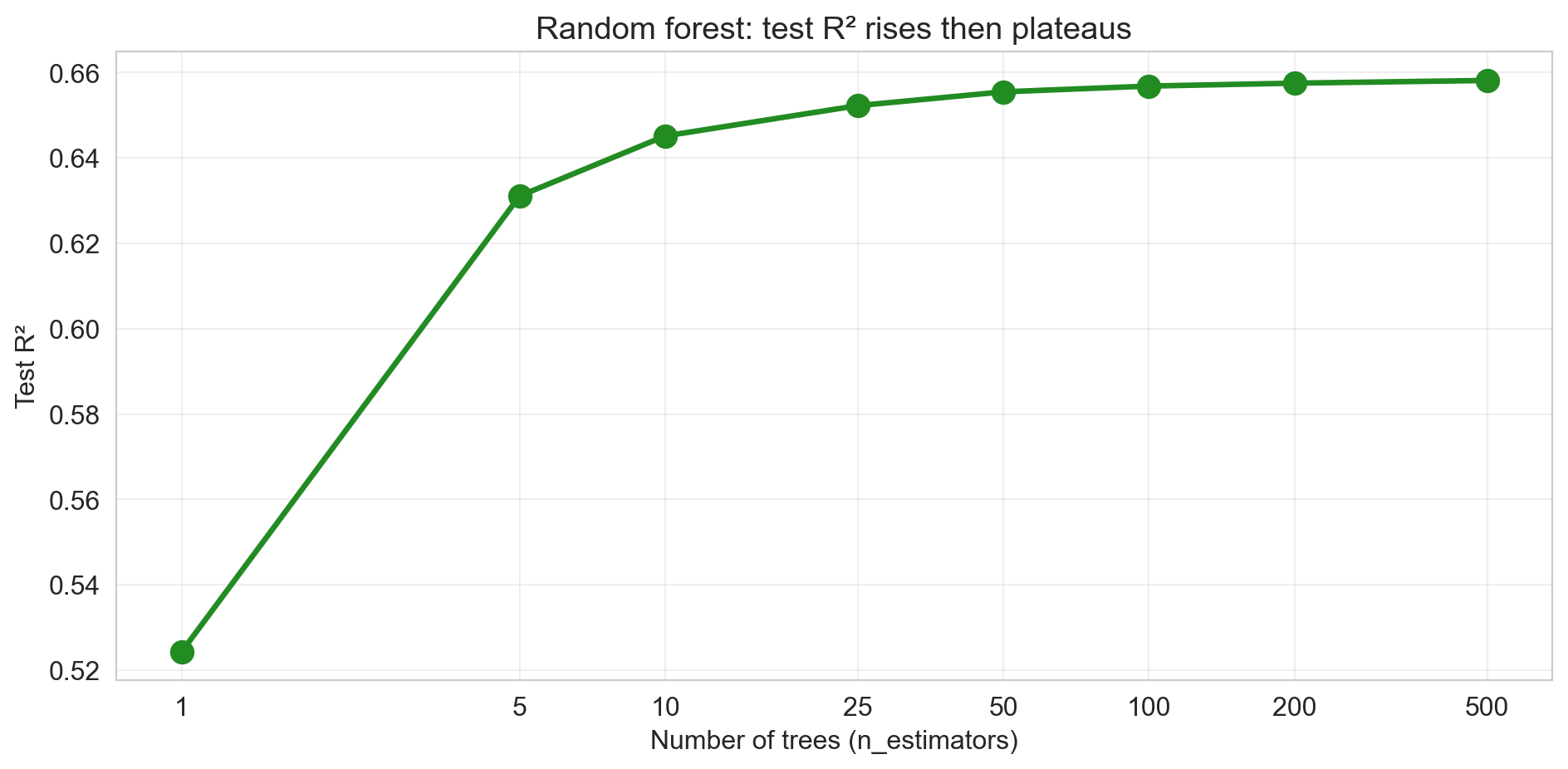
- no U-curve in
n_estimators: staircase replaces the bias-variance tradeoff - depth is the bias-variance lever, B is variance-only
trees vs. linear, two synthetic problems
what the forest uses
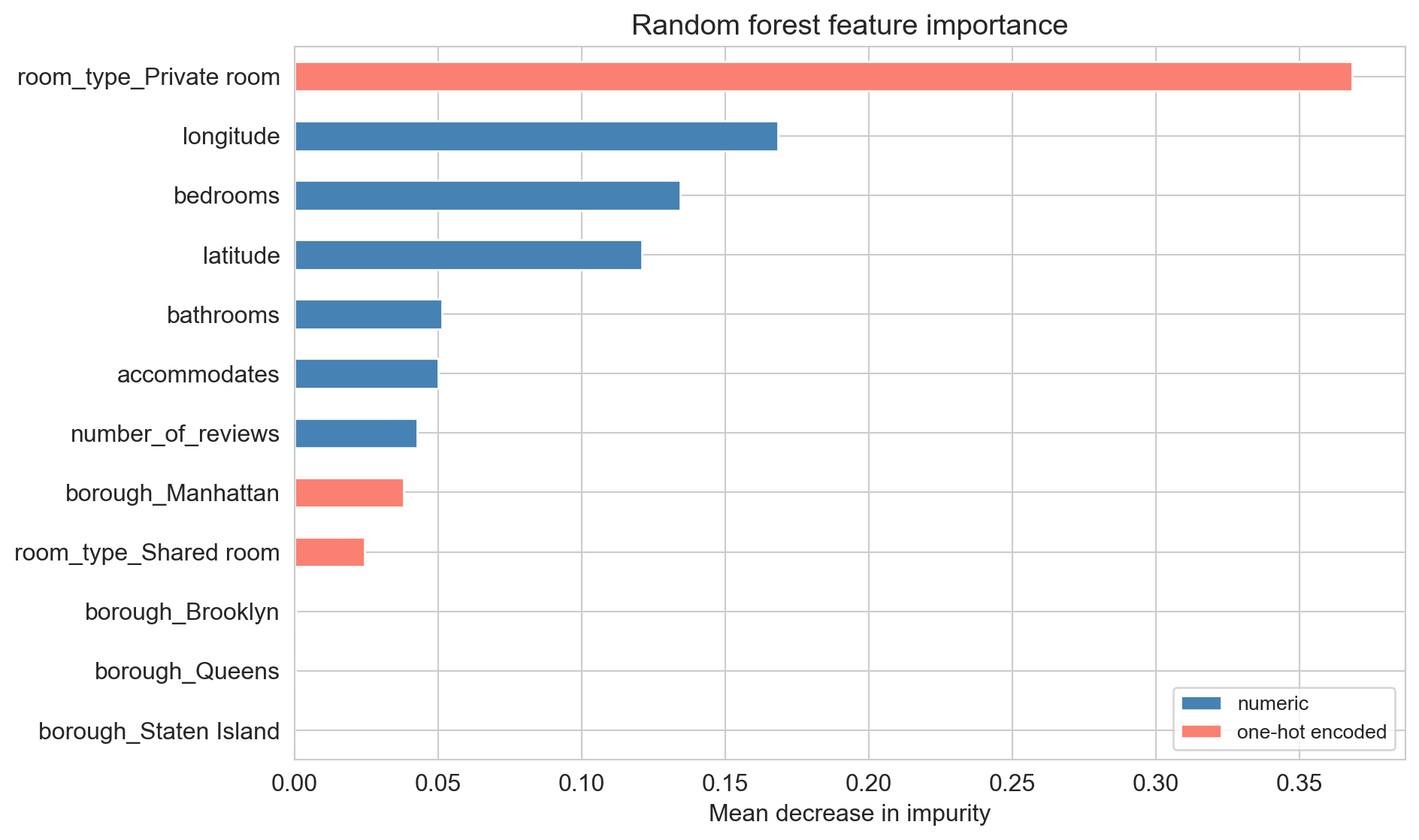
high MDI ≠ “this feature causes the outcome”. only “the forest splits on it”
MDI vs. permutation importance
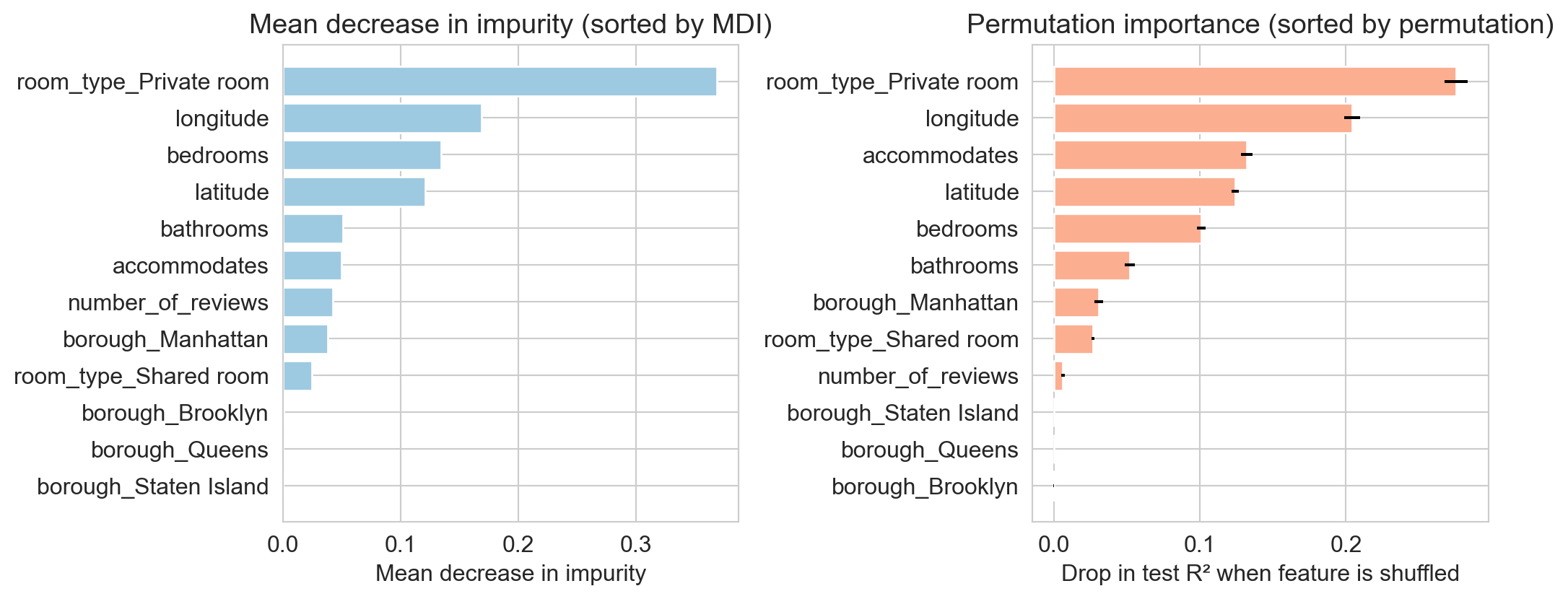
- MDI: counts split chances, biased toward continuous, high-cardinality columns
- permutation: measures held-out R^2 drop after shuffling a column, model-agnostic but slow
distribution shift: linear vs. forest extrapolation
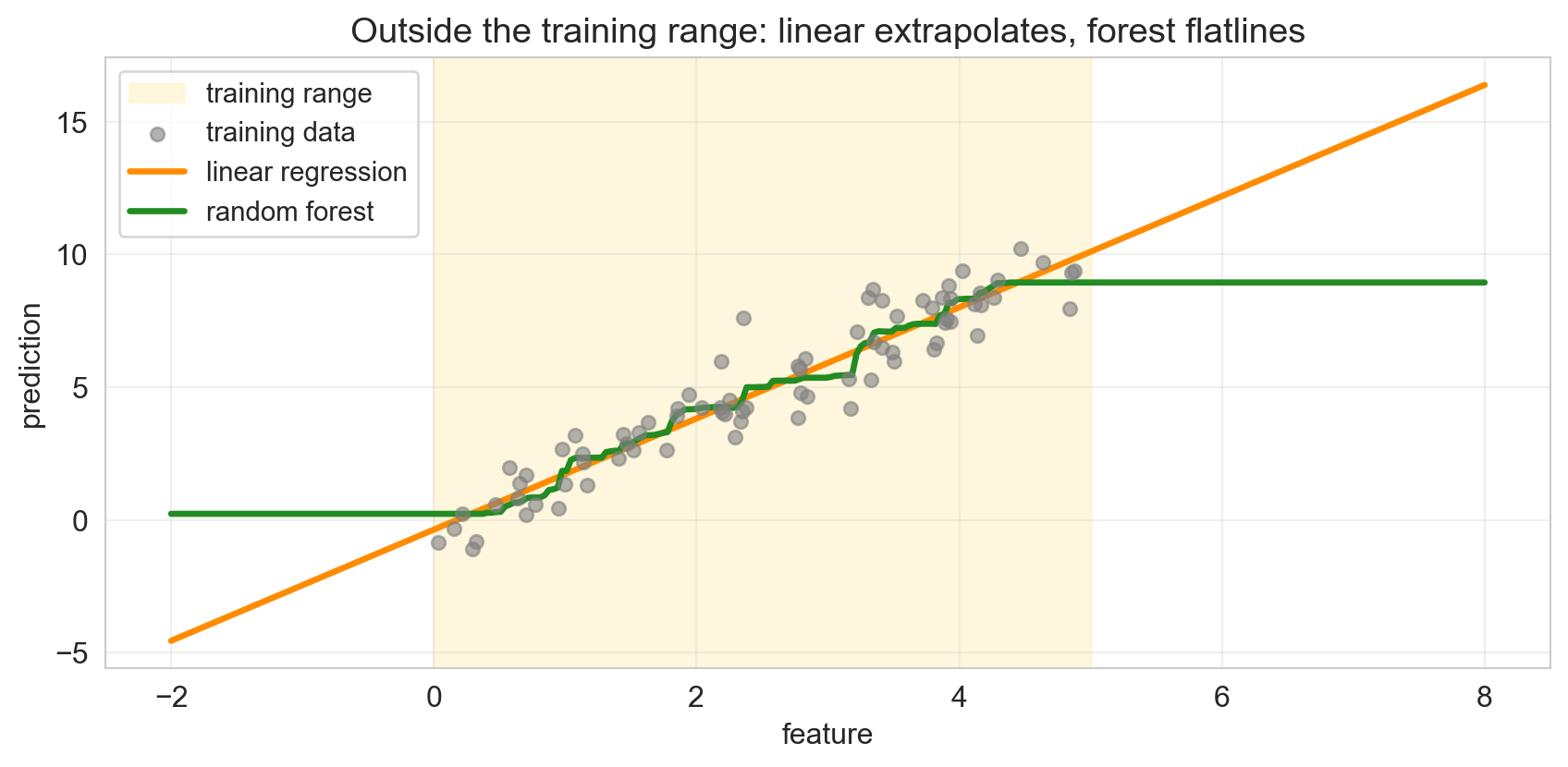
- linear extends its slope past the training range
- forest flatlines: predicts the nearest leaf’s mean
feedback

what worked? what didn’t? what’s still confusing?