Lecture 8: Bootstrap and the Normal Approximation
MSE 125 — Applied Statistics
Wednesday, April 22, 2026
but the spread is enormous
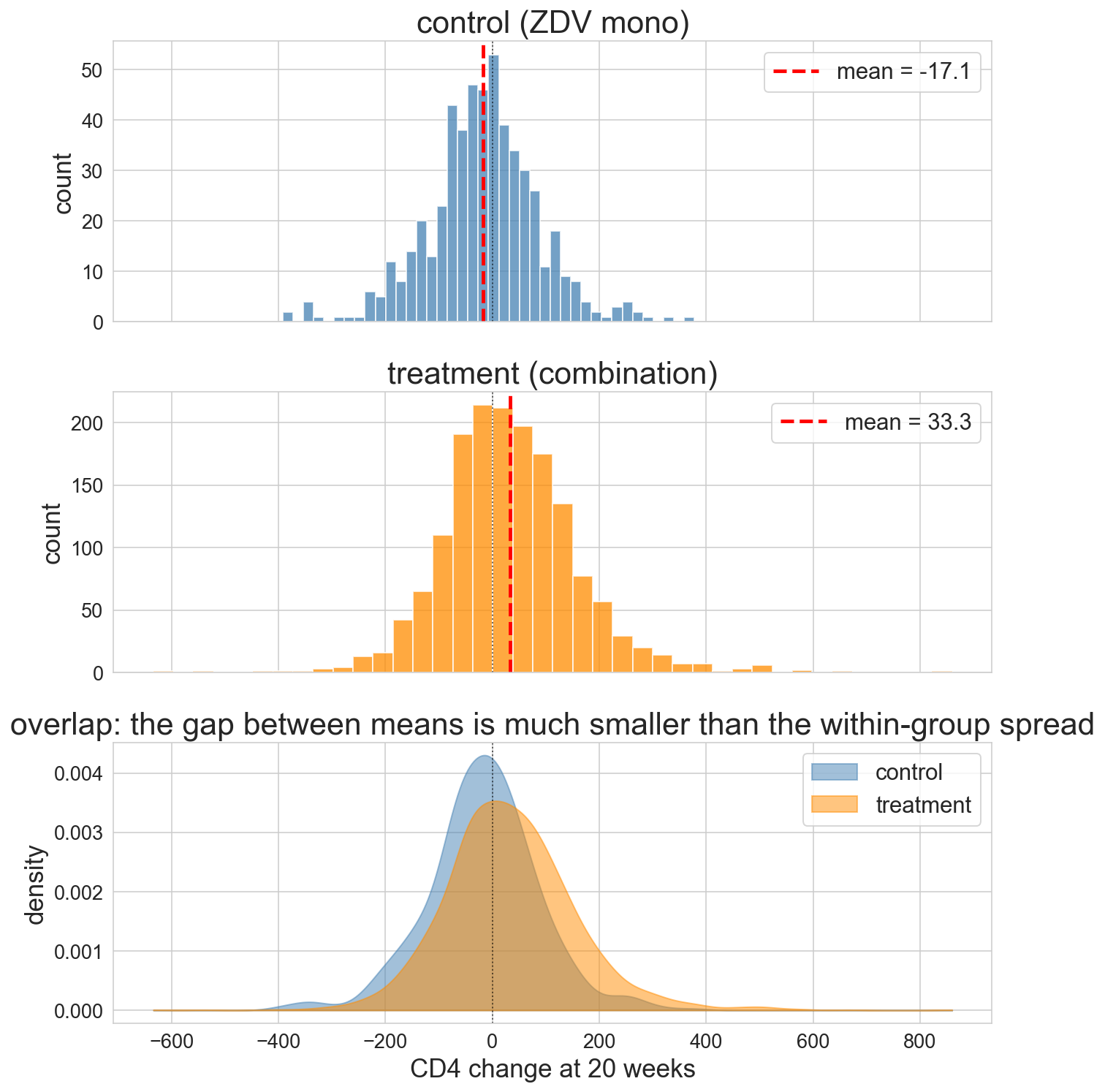
red dashed = group mean
the overlap is bigger than the gap
sampling distribution
sampling distribution
the distribution of values a statistic would take if we could repeat the study many times, each time with a fresh sample from the population
the three sub-trials above are three draws from this distribution
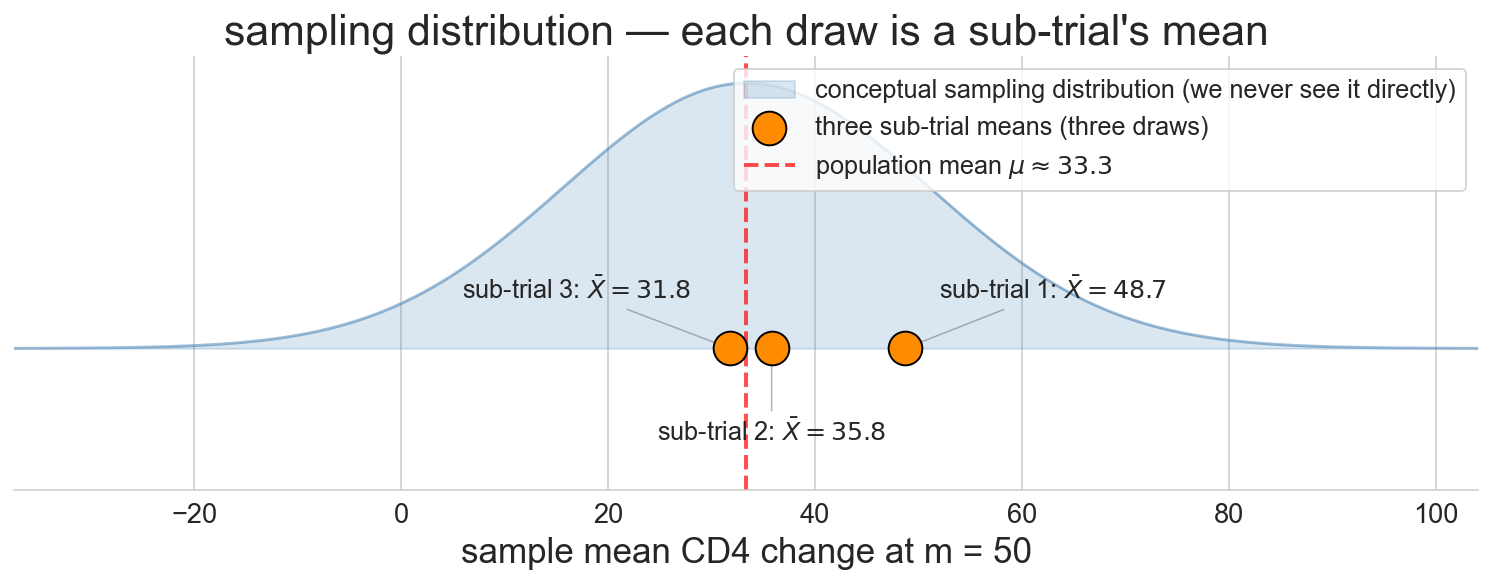
we never see it directly. we have one sample, not many
what a resample looks like
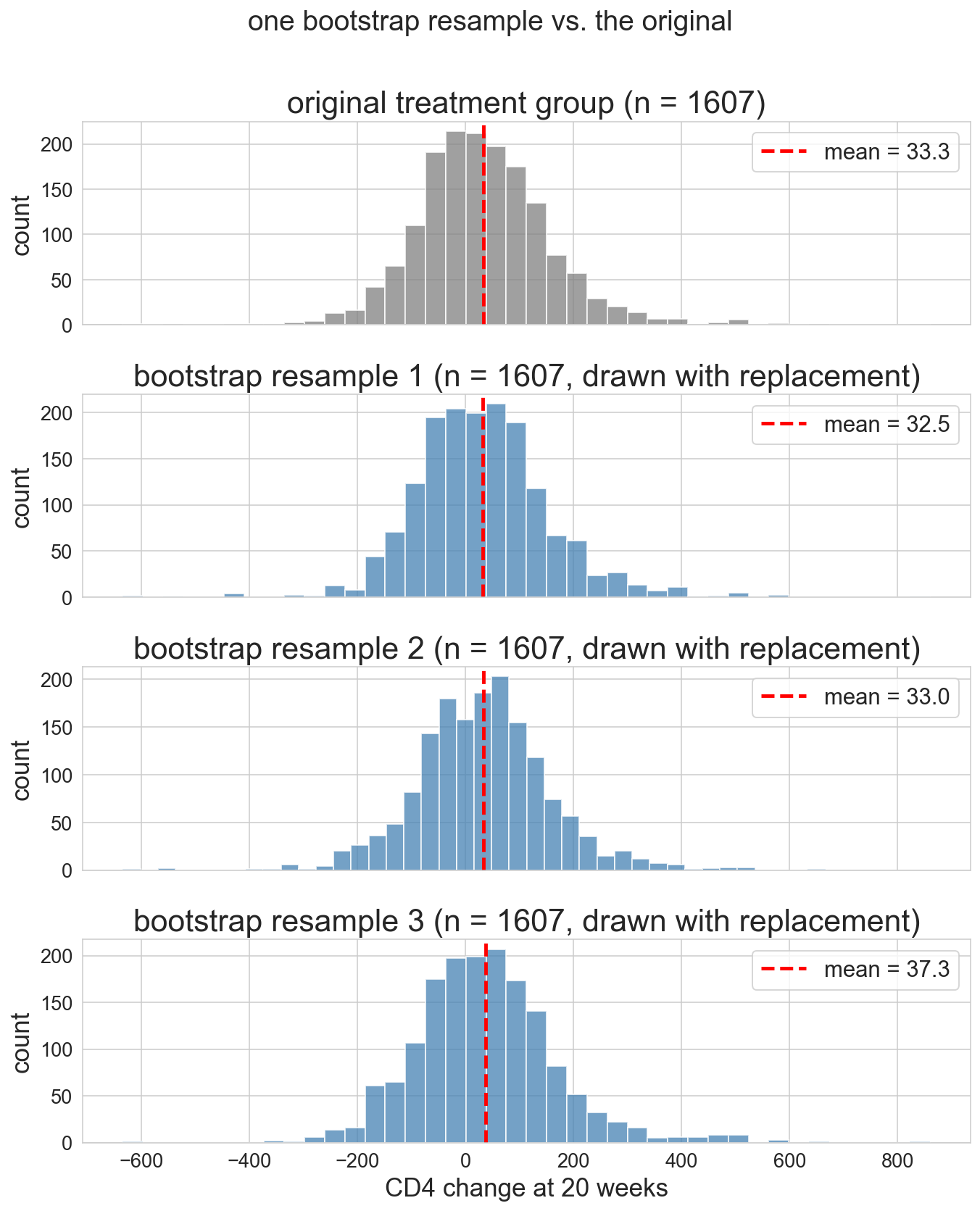
- original on top
- three resamples below
- same size, slightly different composition, slightly different mean
the bootstrap distribution
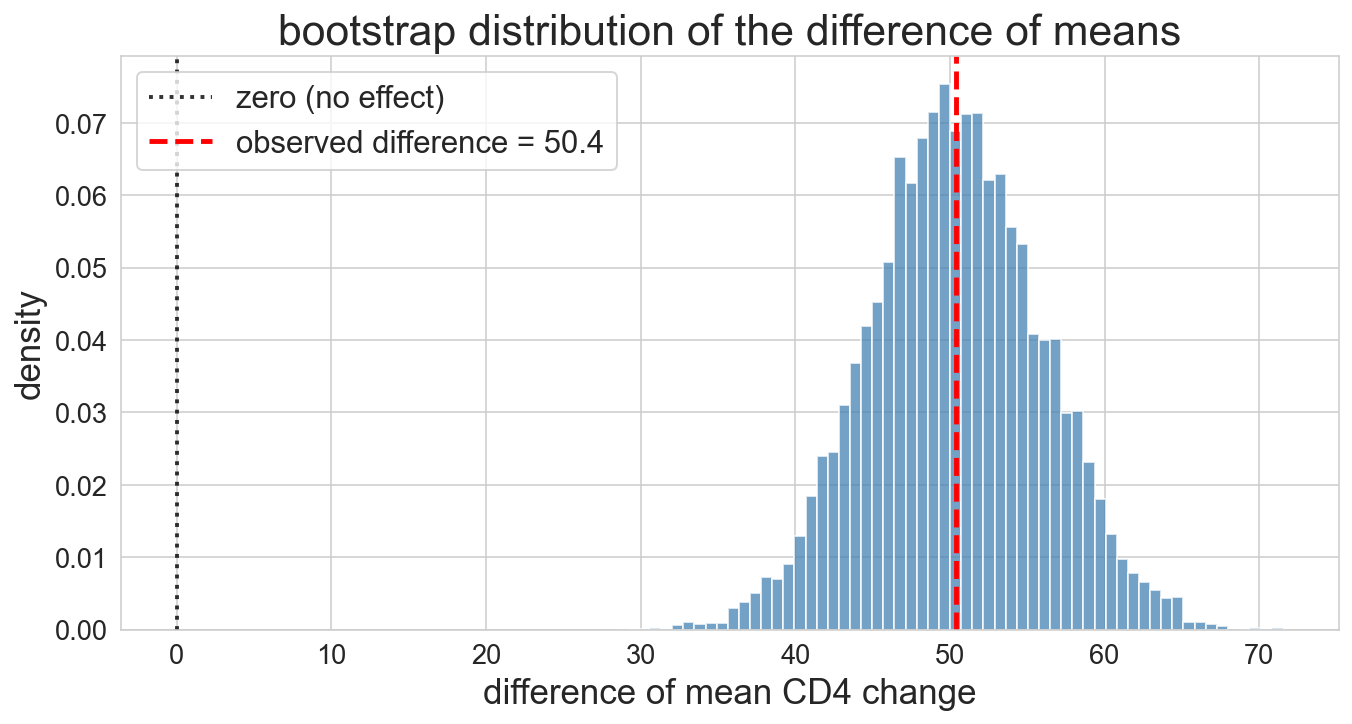
10,000 resamples mapping out the shape of plausible values
our third distribution today, after \mathcal{X} and the sampling distribution of \bar X_n
and the CI is…
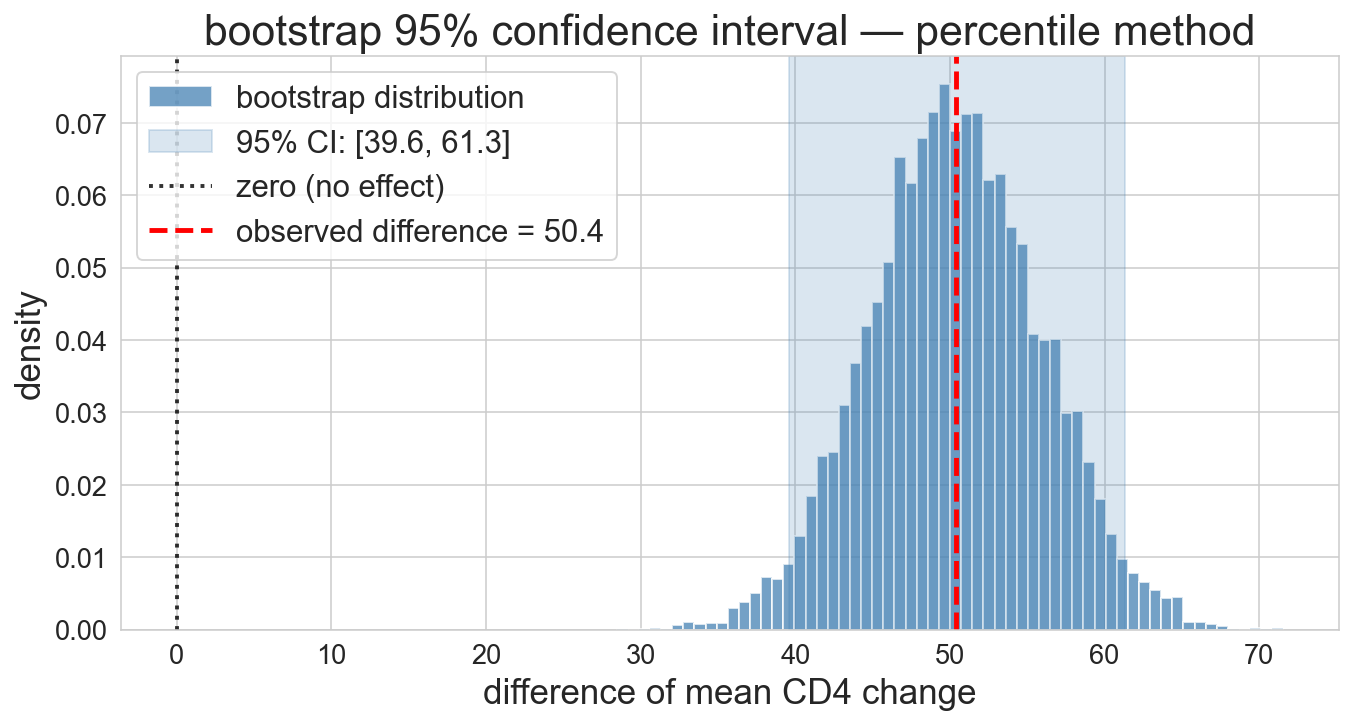
95% CI: [39.6, 61.3]
entirely above zero. the drug really works
the bootstrap distribution looks… bell-shaped?
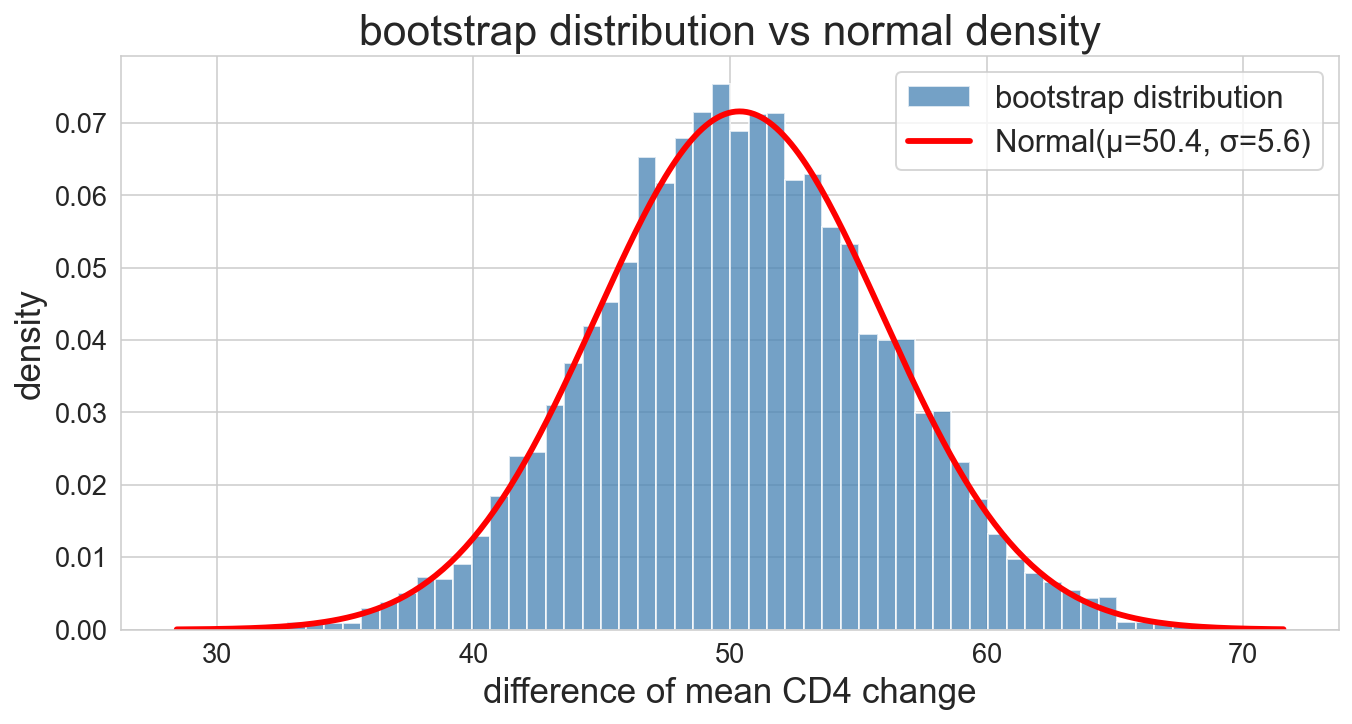
red curve = Normal(μ, σ) with bootstrap mean and SD. nearly perfect fit
Central Limit Theorem: informal
if you average many independent draws from a population distribution \mathcal{X}, the result is approximately normal, for large enough sample size
the sample mean is bell-shaped even if \mathcal{X} isn’t
the bootstrap distribution is a sampling distribution of a sample mean. so: bell-shaped
the CLT in action: watch the bell sharpen
notation in one place:
- n_T, n_C: actual trial group sizes (1607, 532)
- m: hypothetical sample size we vary across demos
- B: outer-loop count (here 10,000); CLT scales with m, not B
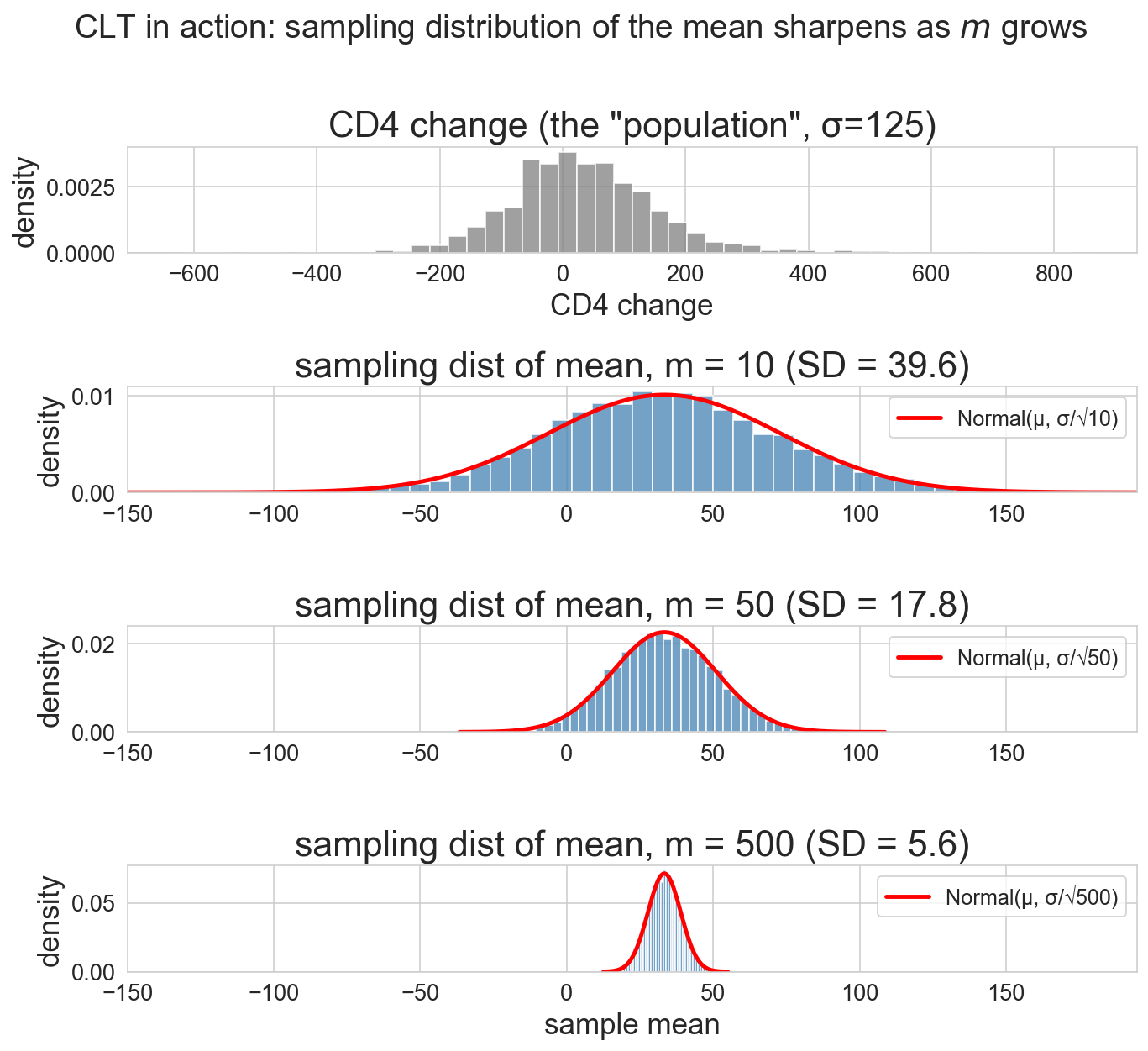
draw samples of size m from CD4 data
four panels: population, m=10, m=50, m=500
bootstrap vs formula: head to head
| approach | \widehat{\text{SE}} | 95% CI |
|---|---|---|
| bootstrap, 10,000 resamples | 5.6 | [39.6, 61.3] |
| normal formula | 5.6 | [39.6, 61.2] |
both columns estimate the true SE, so we write \widehat{\text{SE}}
they agree. so why do we teach both?
analytical planning: how big a trial?
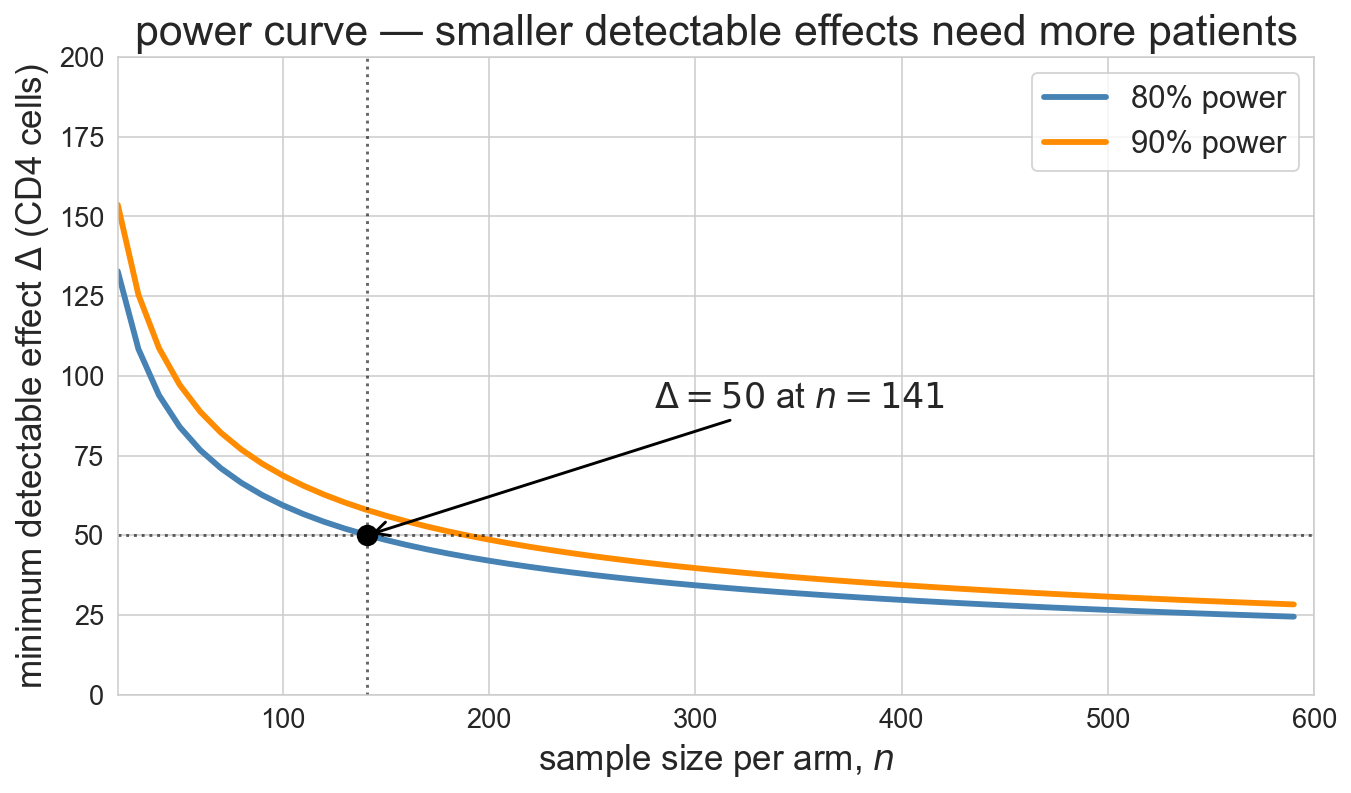
before ACTG 175 enrolled a patient, NIH had to answer: how many patients?
- target detectable effect: \Delta = 50 CD4 cells
- illustrative SD guess from pilot data: \sigma \approx 150 per arm
- 80% power
- significance \alpha = 0.05
z_{\alpha/2} = 1.96 (two-sided 5% critical value), z_\beta = 0.84 (80th percentile of N(0,1))
n \;=\; \frac{2\sigma^2 \,(z_{\alpha/2} + z_\beta)^2}{\Delta^2} \;=\; \frac{2 \cdot 150^2 \cdot (1.96 + 0.84)^2}{50^2} \;\approx\; 141 \text{ per arm}
formula assumes equal group sizes (trial design choice)
bootstrap can’t do this. no data yet to resample
failure mode 1: the median
CLT applies to means, not medians
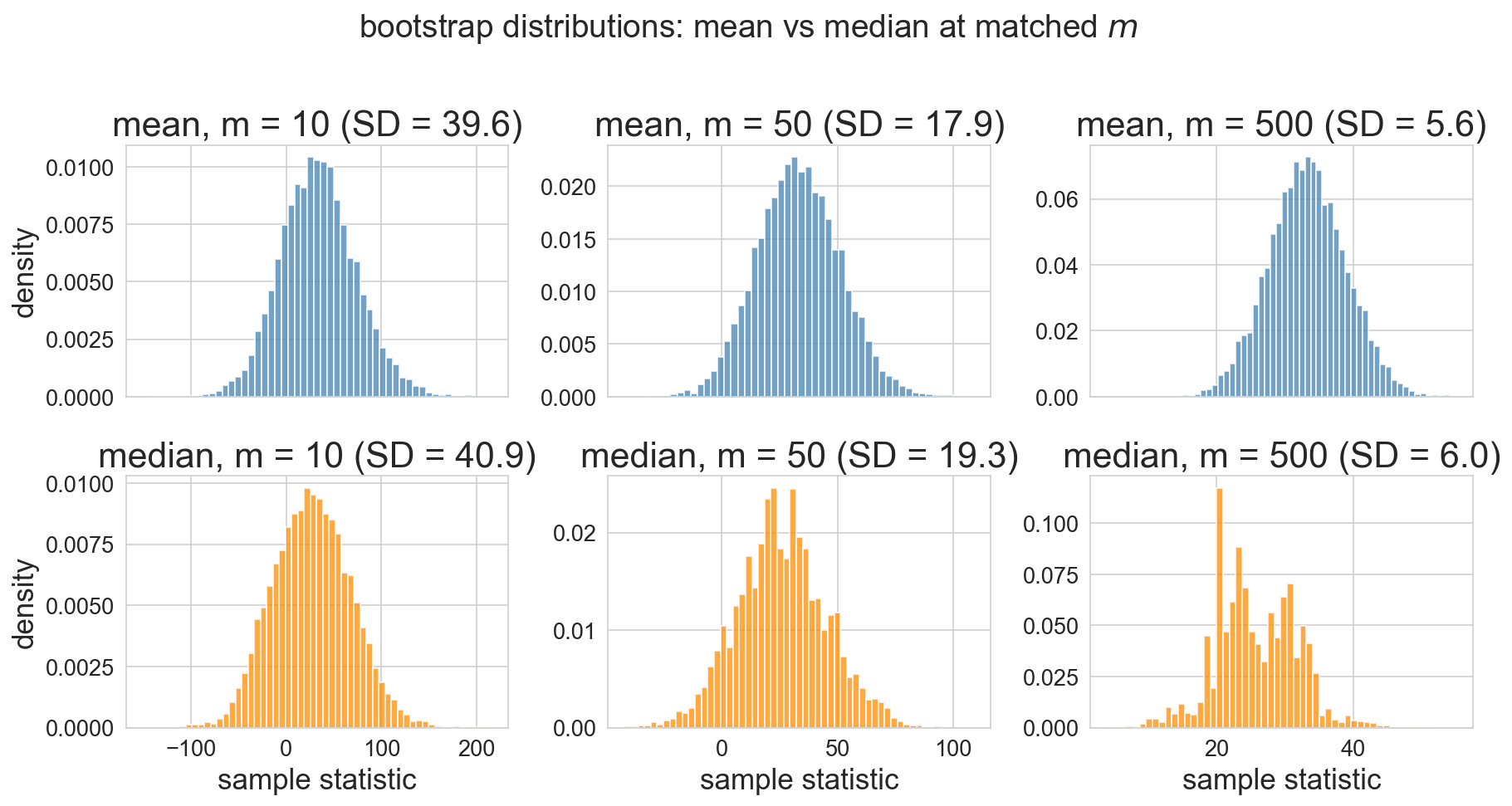
median’s bootstrap distribution is lumpier, wider, no simple closed-form SE
failure mode 2: heavy tails at small m
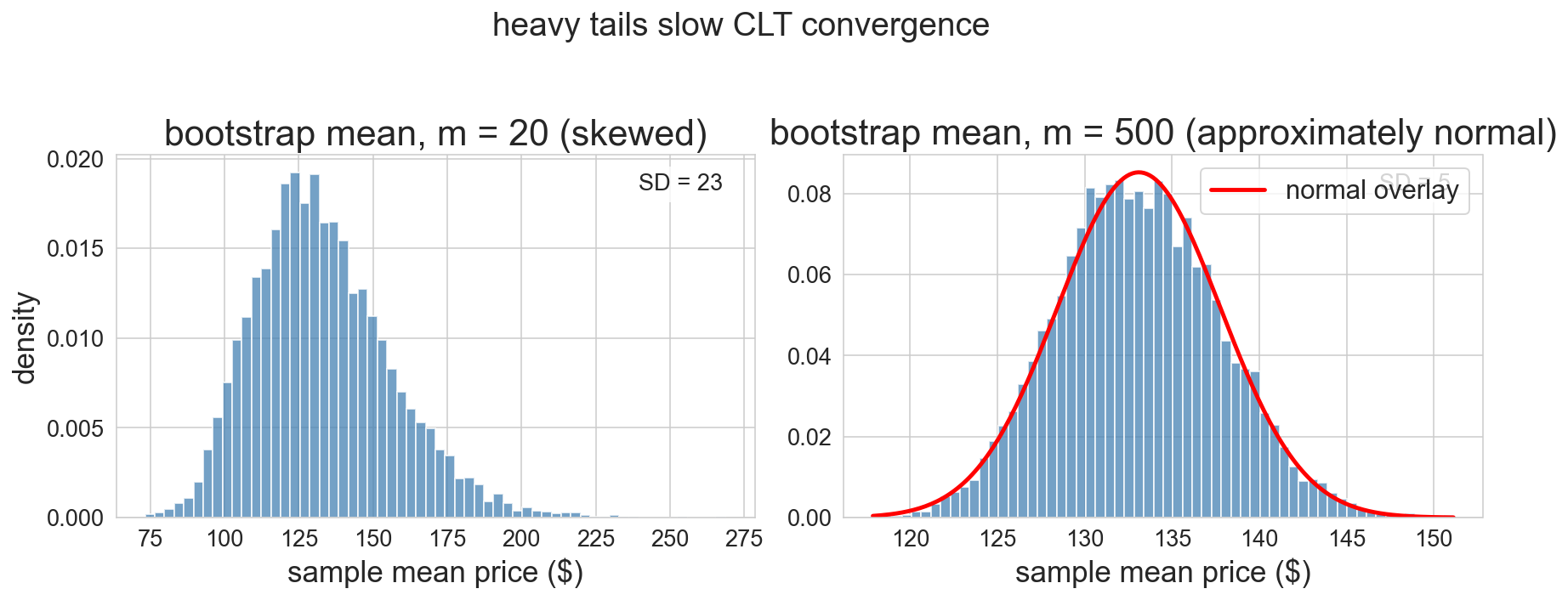
m=20 with right-skewed prices: bootstrap itself is skewed. normal CI would lie
m=500: CLT has kicked in
one-minute feedback
- what was the most useful thing you learned today?
- what was the most confusing?
