Lecture 7: Classification — Logistic Regression and Metrics
MSE 125 — Applied Statistics
Monday, April 20, 2026
can we just run linear regression?
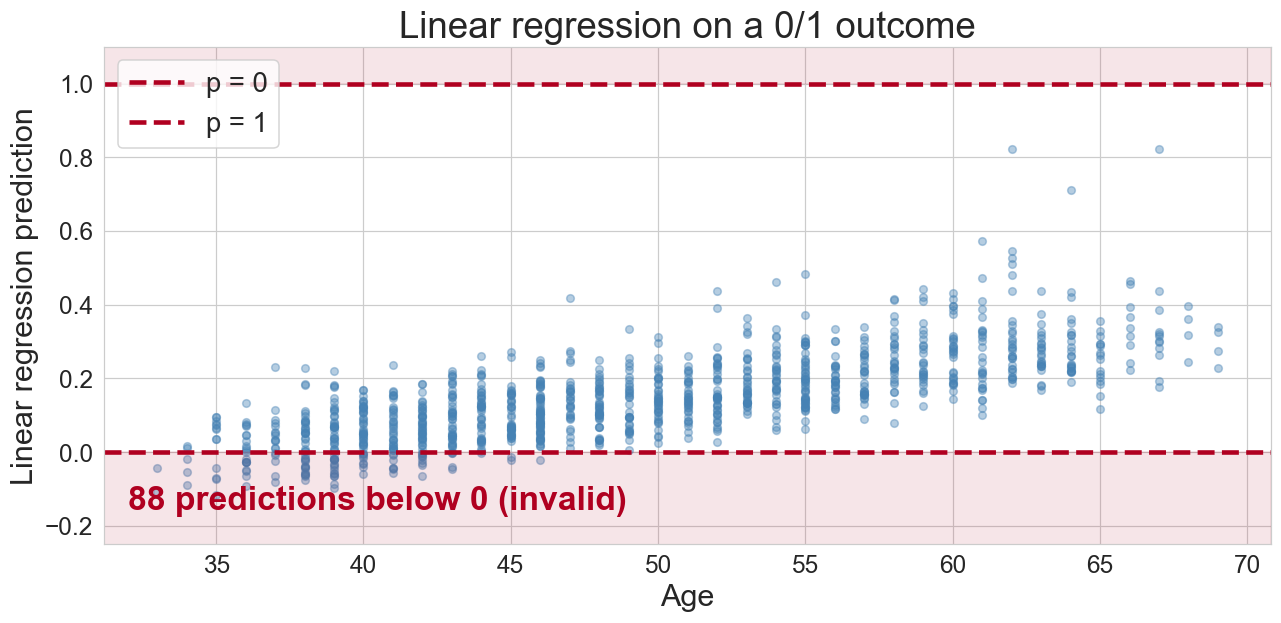
predictions below 0 and above 1: not valid probabilities
the trick: squeeze the line through a sigmoid
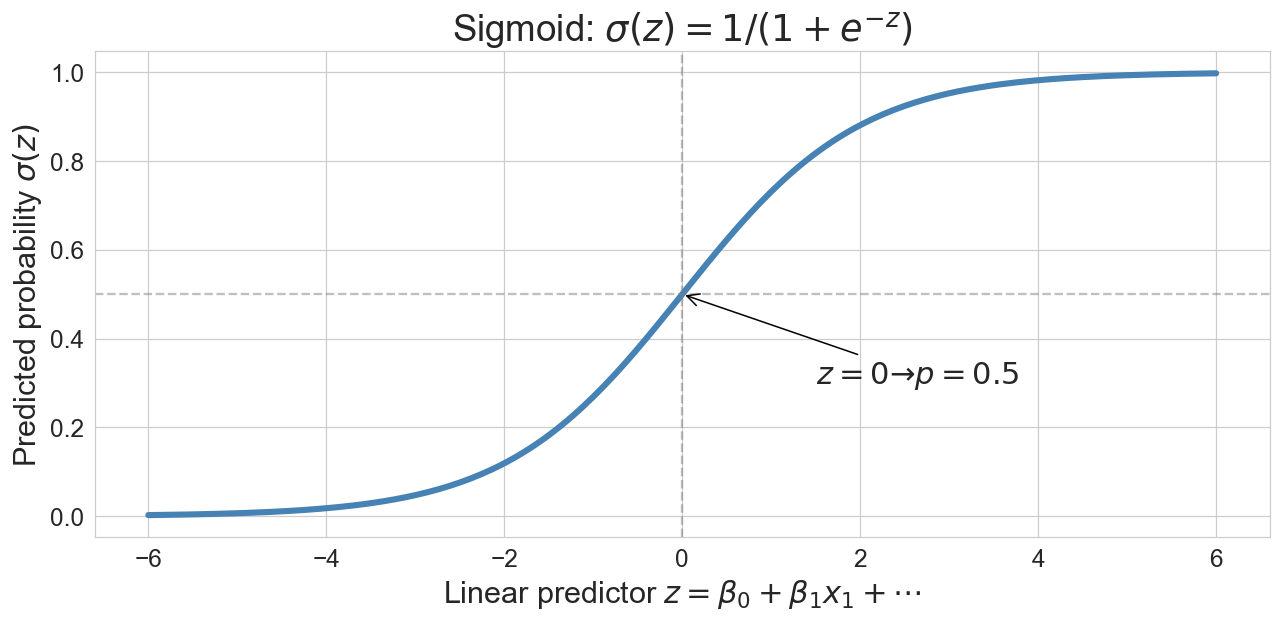
\[p = \sigma(z) = \frac{1}{1 + e^{-z}}, \quad z = \beta_0 + \beta_1 x_1 + \cdots + \beta_d x_d\]
logistic regression on age alone
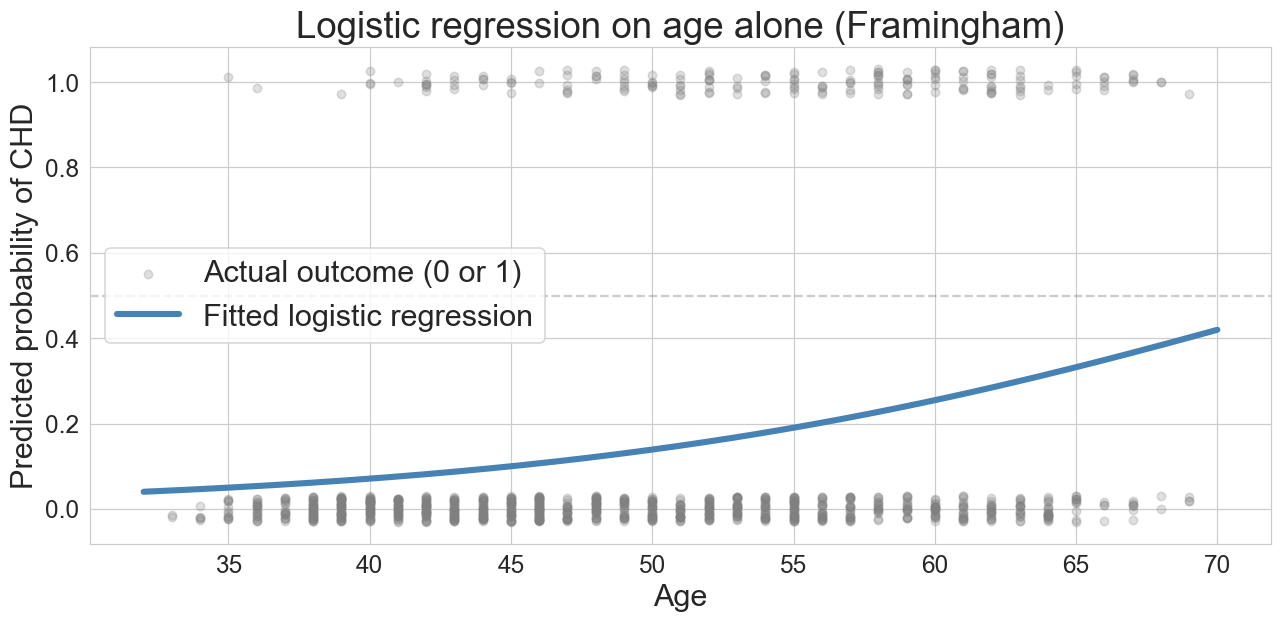
predicted risk climbs with age. we see the lower portion of the S-curve because the base rate is low
squared error vs. logistic loss
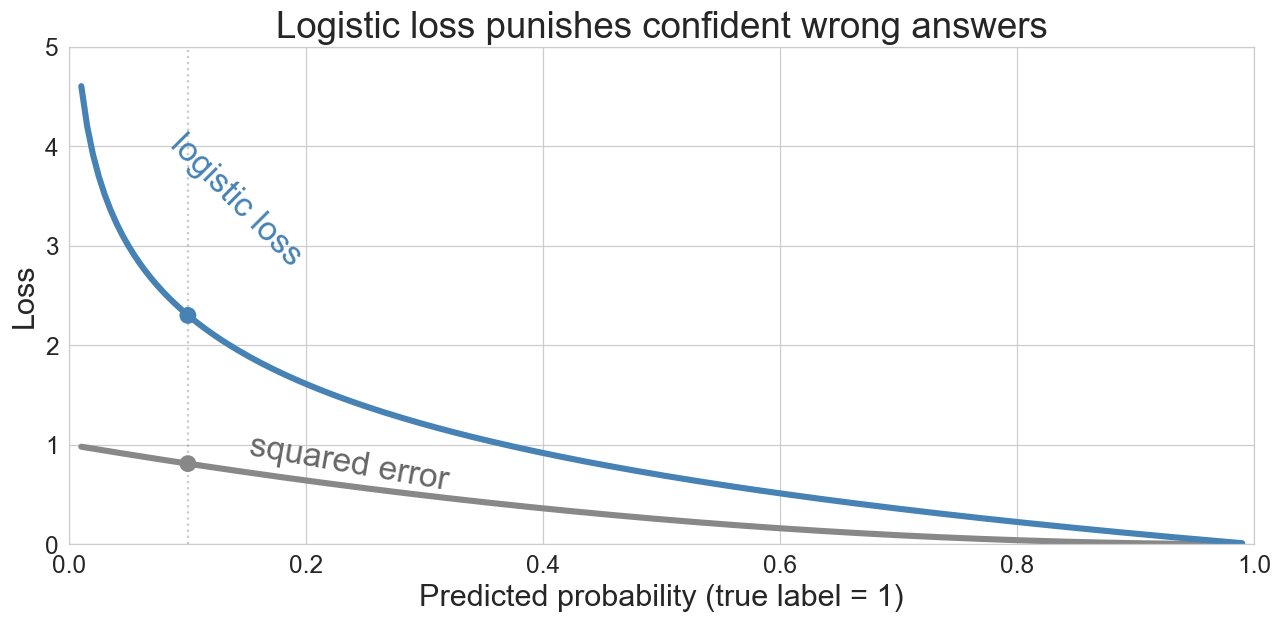
a 10% prediction for a true 1? squared error 0.81, logistic loss 2.3
the loss function determines what the model finds
gradient descent: hiking downhill
\[\beta \leftarrow \beta - \eta \cdot \nabla L(\beta)\]
- \(\nabla L(\beta)\) = gradient (uphill direction); step the opposite way
- \(\eta\) = learning rate (step size)
logistic loss is convex: one valley, no false minima
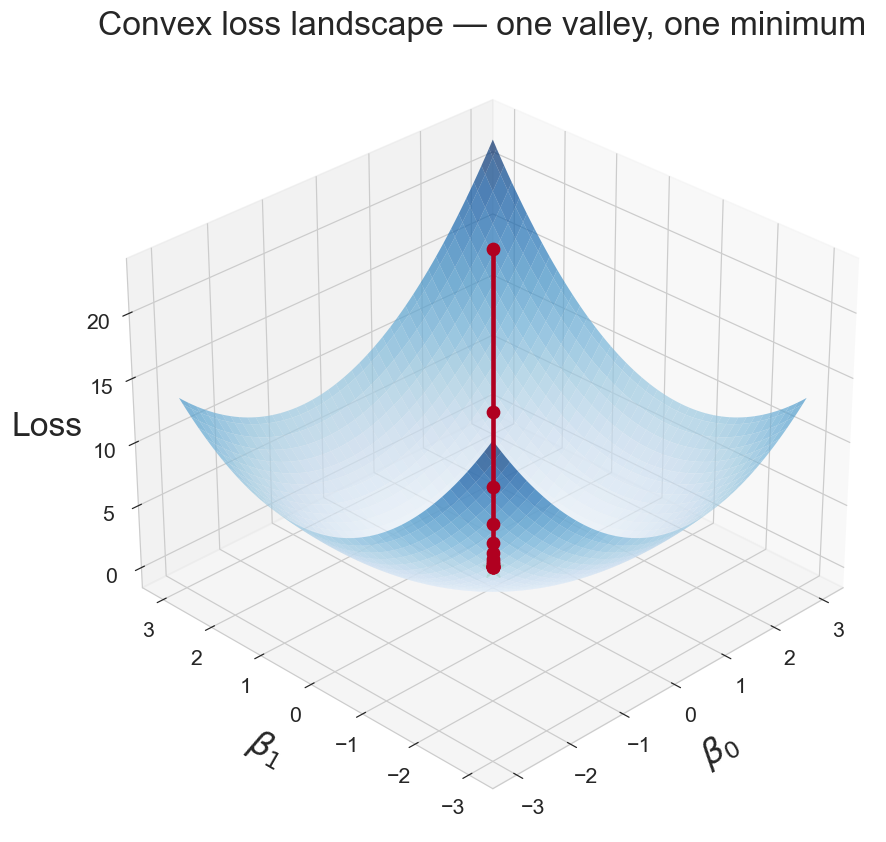
watch it converge
Q: will the loss curve drop smoothly, oscillate, or bounce around?
commit to a prediction. then we run 50 iterations
watch it converge
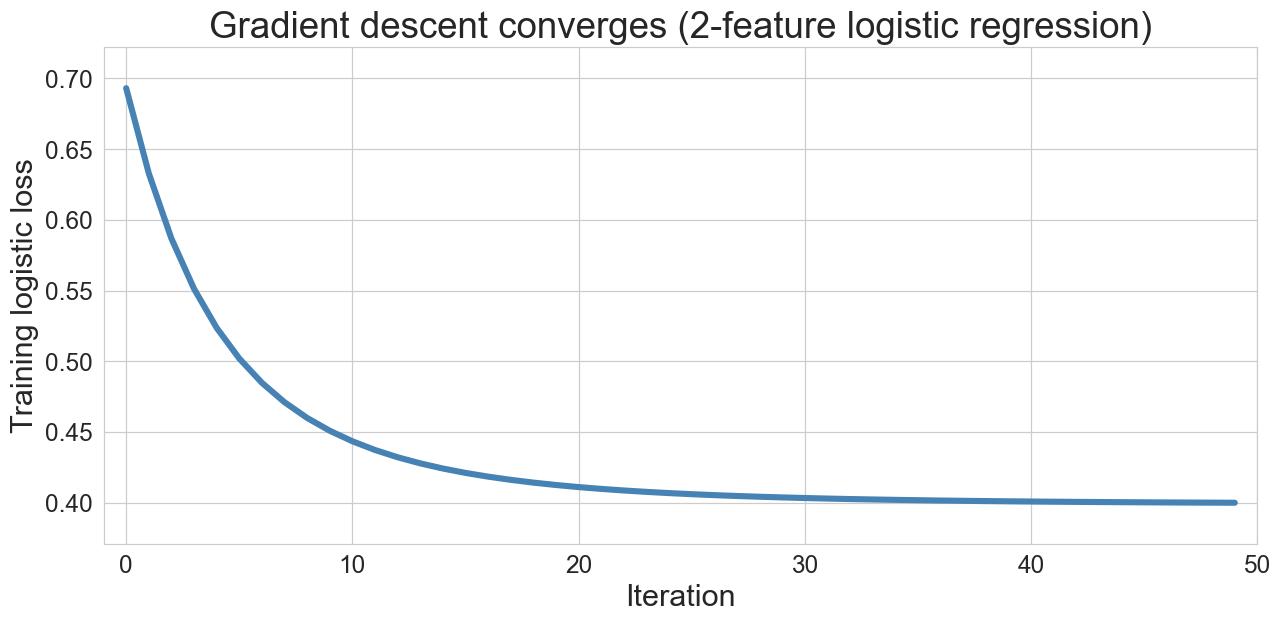
50 iterations on age + BMI (body mass index) logistic regression. loss drops fast, then settles.
but wait
the “always predict no CHD” baseline:
Q: what accuracy does it get?
baseline accuracy = 0.848
our model accuracy = 0.855
improvement = 0.007our fancy classifier barely beats the null
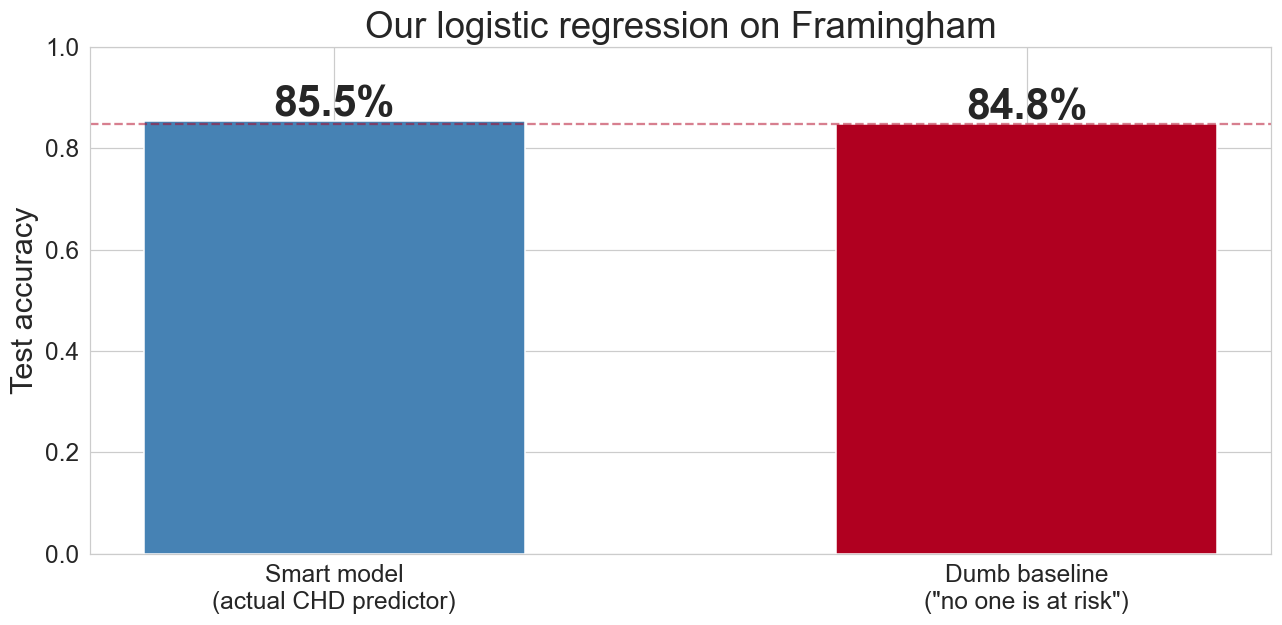
accuracy measures how often you’re right overall. when one class dominates, that’s easy and uninformative
the confusion matrix
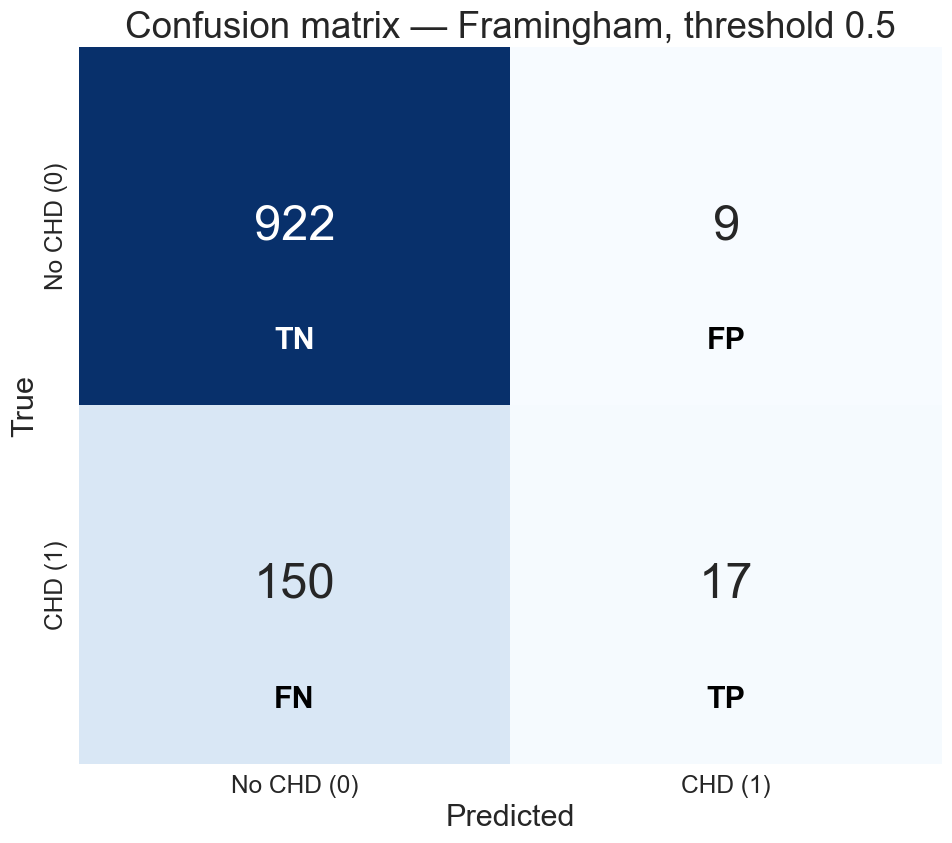
of 167 actual CHD cases, we caught 17
precision-recall across thresholds
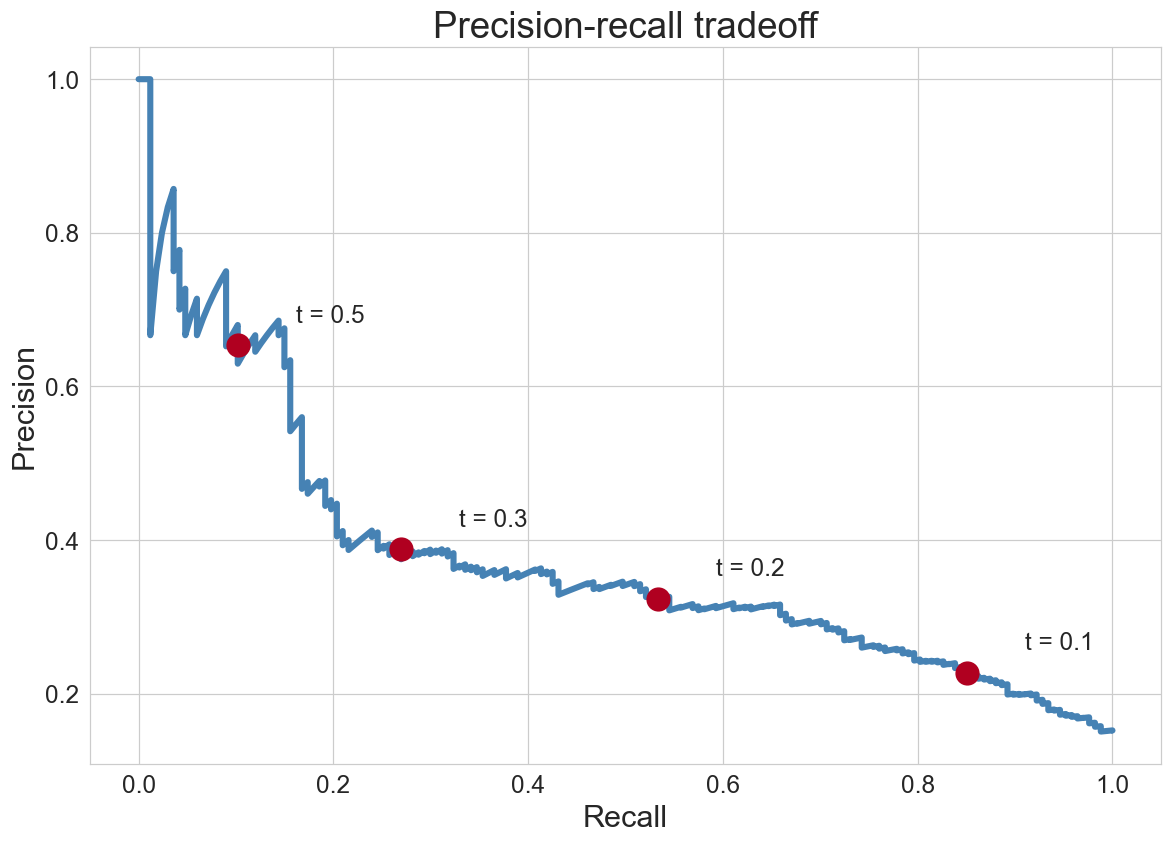
each annotated point is one threshold. as recall climbs, precision falls
precision is P(disease | flagged): read the y-axis as trustworthiness of a flag
stop where precision still beats \(p^*\). beyond that, the marginal flag loses money
another view: ROC (receiver operating characteristic)
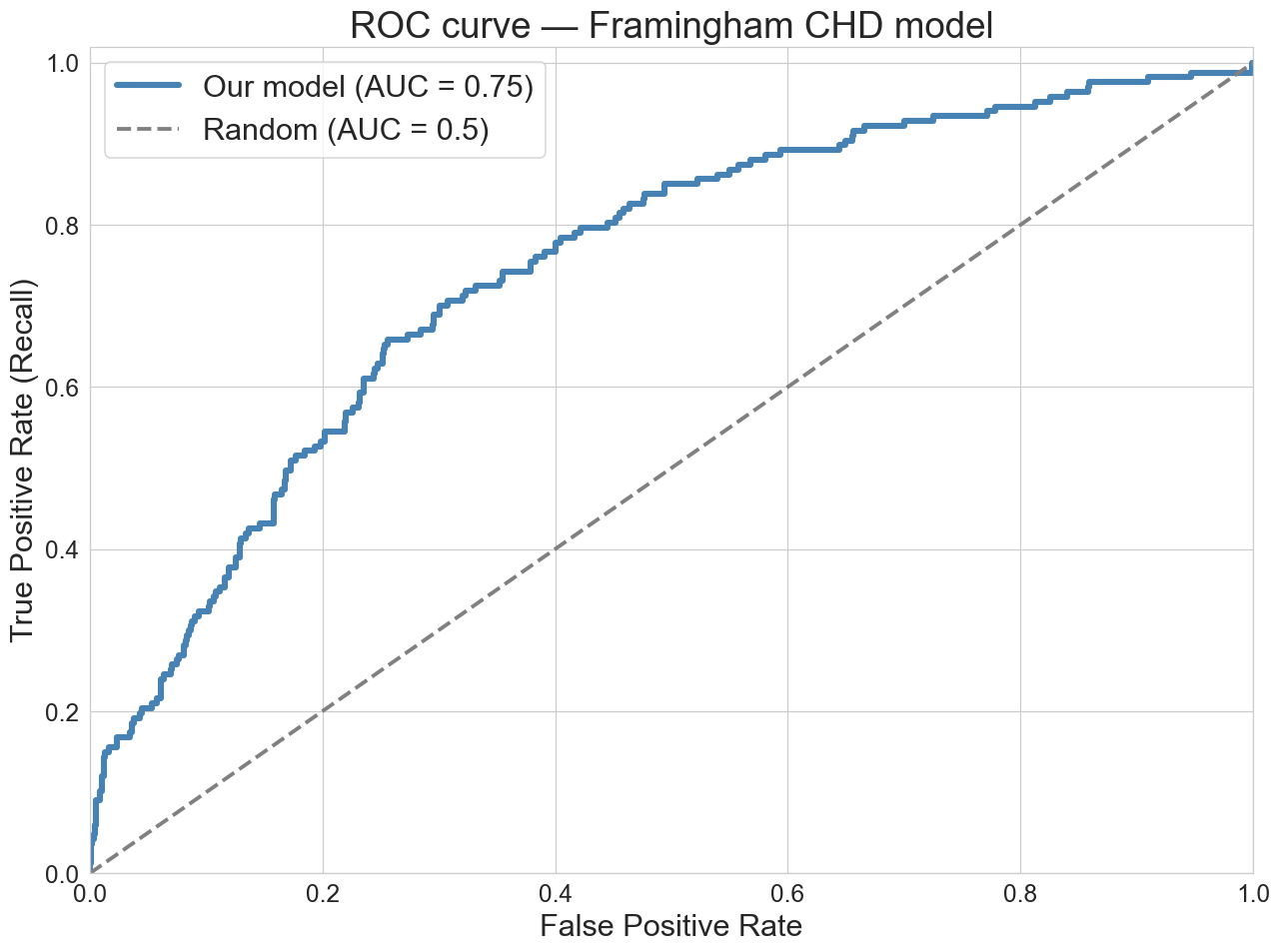
AUC (area under the curve) ≈ 0.75. concordance: pick one CHD and one non-CHD patient; the model ranks the CHD patient higher 75% of the time (ties count as half)
threshold effect on metrics
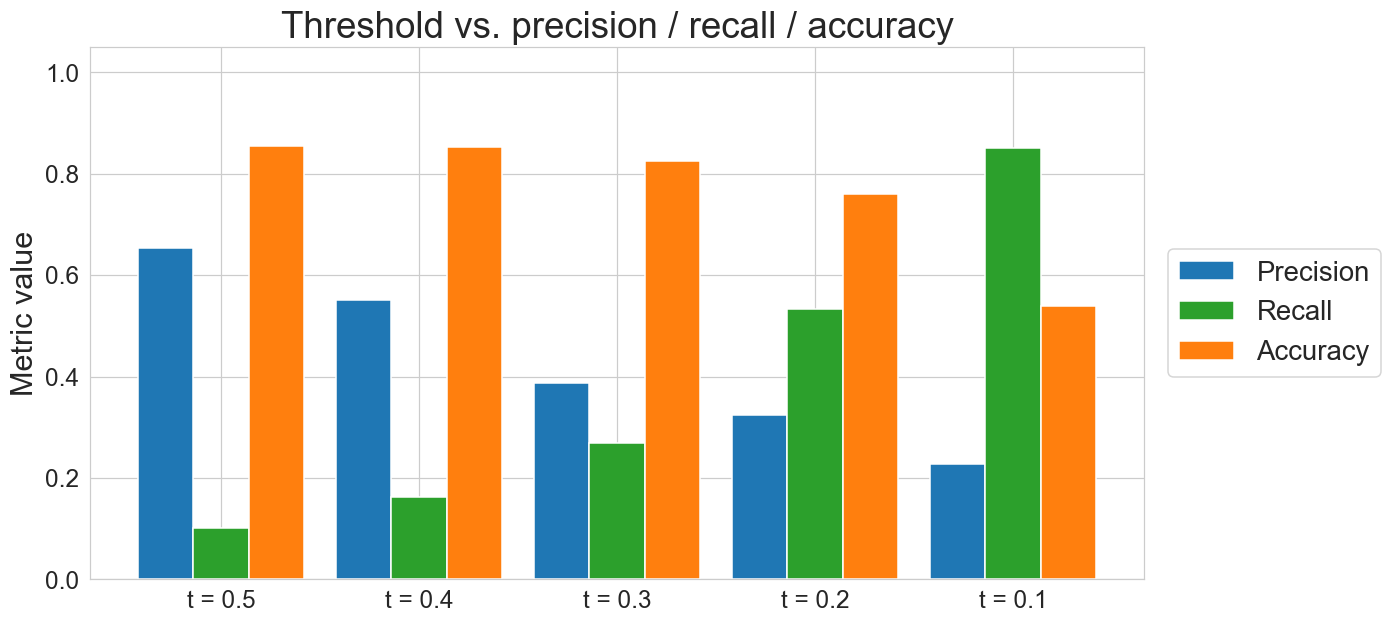
low threshold → catches more, but each flag is less reliable
work it out on 10,000 patients
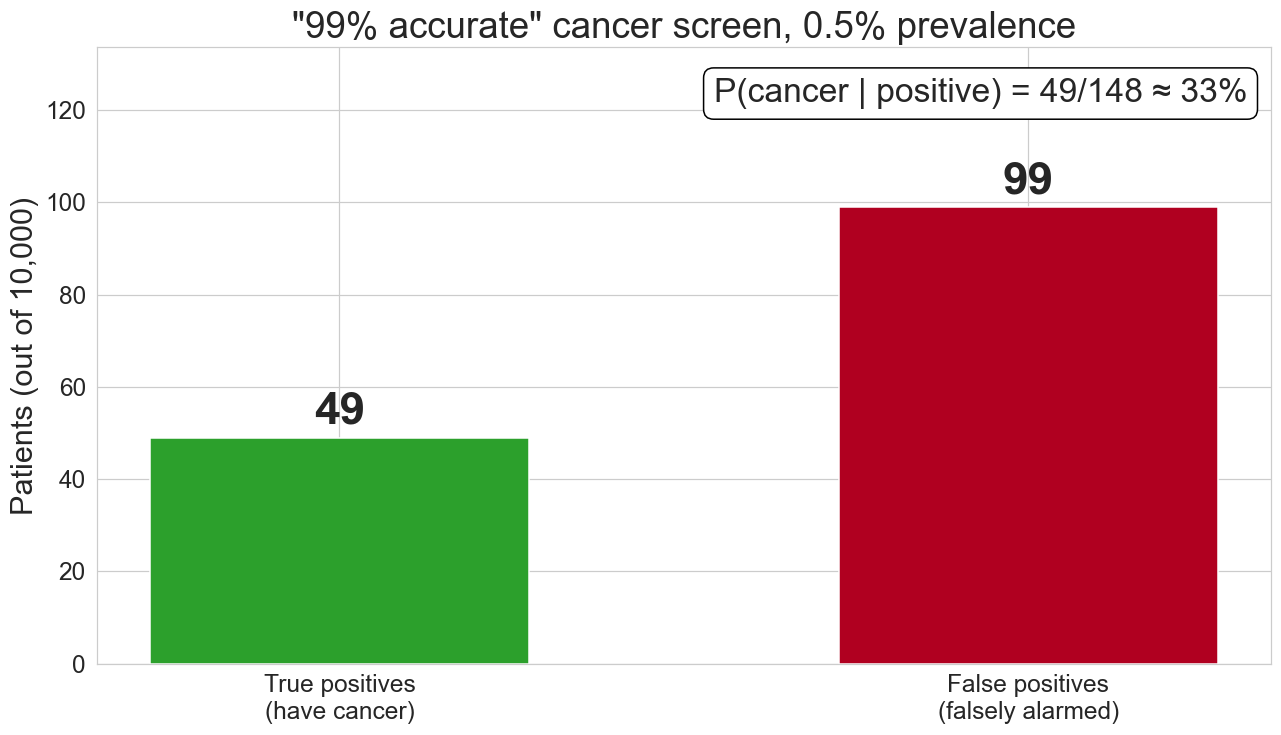
false positives swamp true positives when the condition is rare
subgroup AUC by age
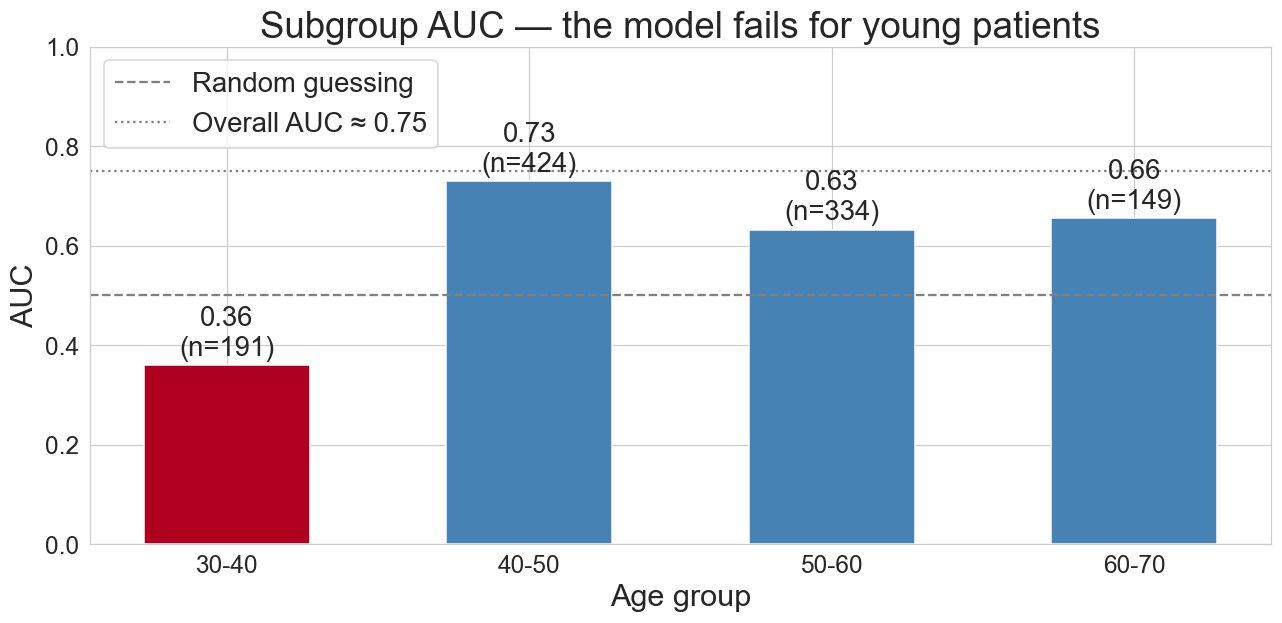
for patients under 40, AUC = 0.36: below 0.5, but based on only ~6 CHD cases; the estimate is noisy
calibration: do probabilities mean what they say?
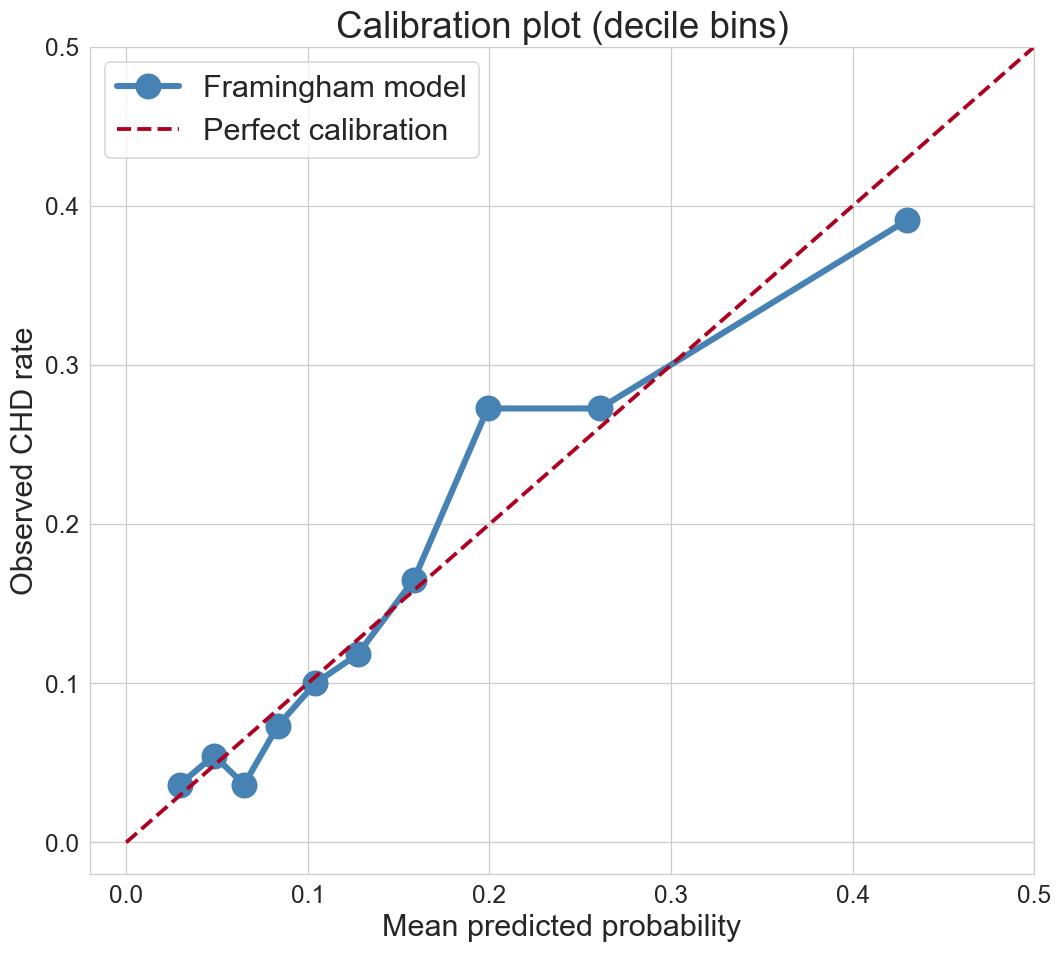
bin predictions into deciles
does “10% risk” mean 10% observed rate?
. . .
AUC measures ranking
calibration measures absolute probabilities
. . .
a model can have good AUC and bad calibration (or vice versa). which matters depends on how you use the output
one-minute feedback
- what was the most useful thing you learned today?
- what was the most confusing?
