Lecture 5: Multiple Regression and Feature Engineering
MSE 125 — Applied Statistics
Monday, April 13, 2026
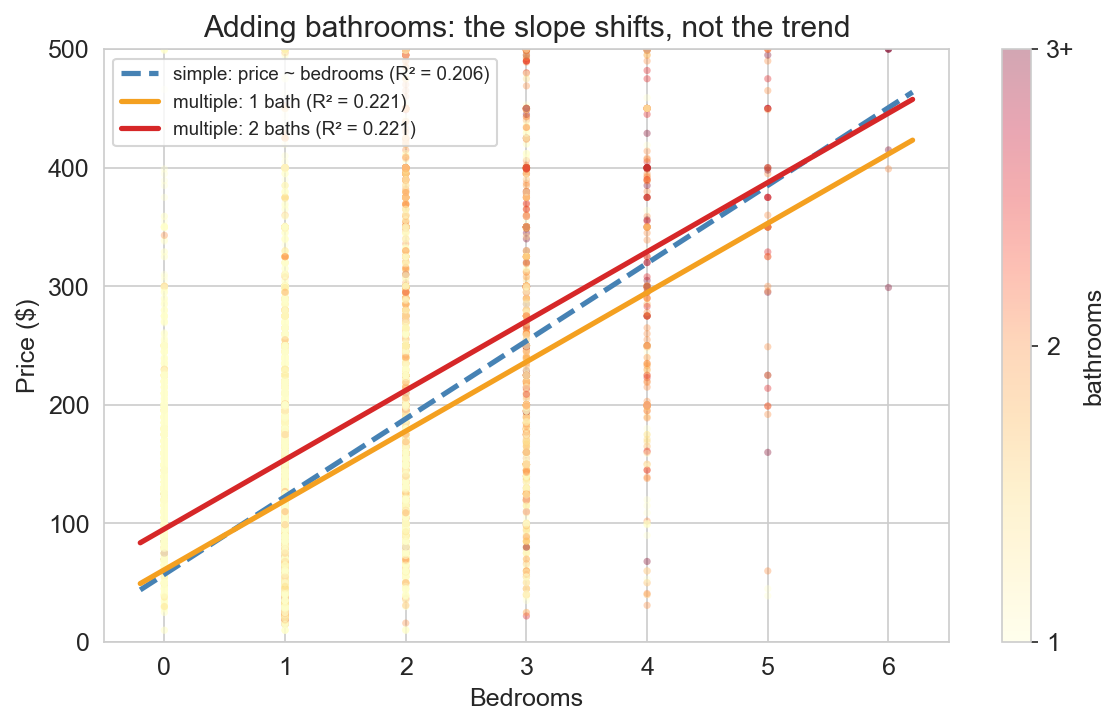
adding bathrooms
chapter 4: \(\widehat{\text{price}} = 57 + 66 \times \text{bedrooms}\)
add bathrooms:
\[\widehat{\text{price}} = 27 + 58 \times \text{bedrooms} + 34 \times \text{bathrooms}\]
a 2BR / 1BA listing: \(27 + 58(2) + 34(1) = \$177\)
a 2BR / 2BA listing: \(27 + 58(2) + 34(2) = \$211\)
the feature matrix
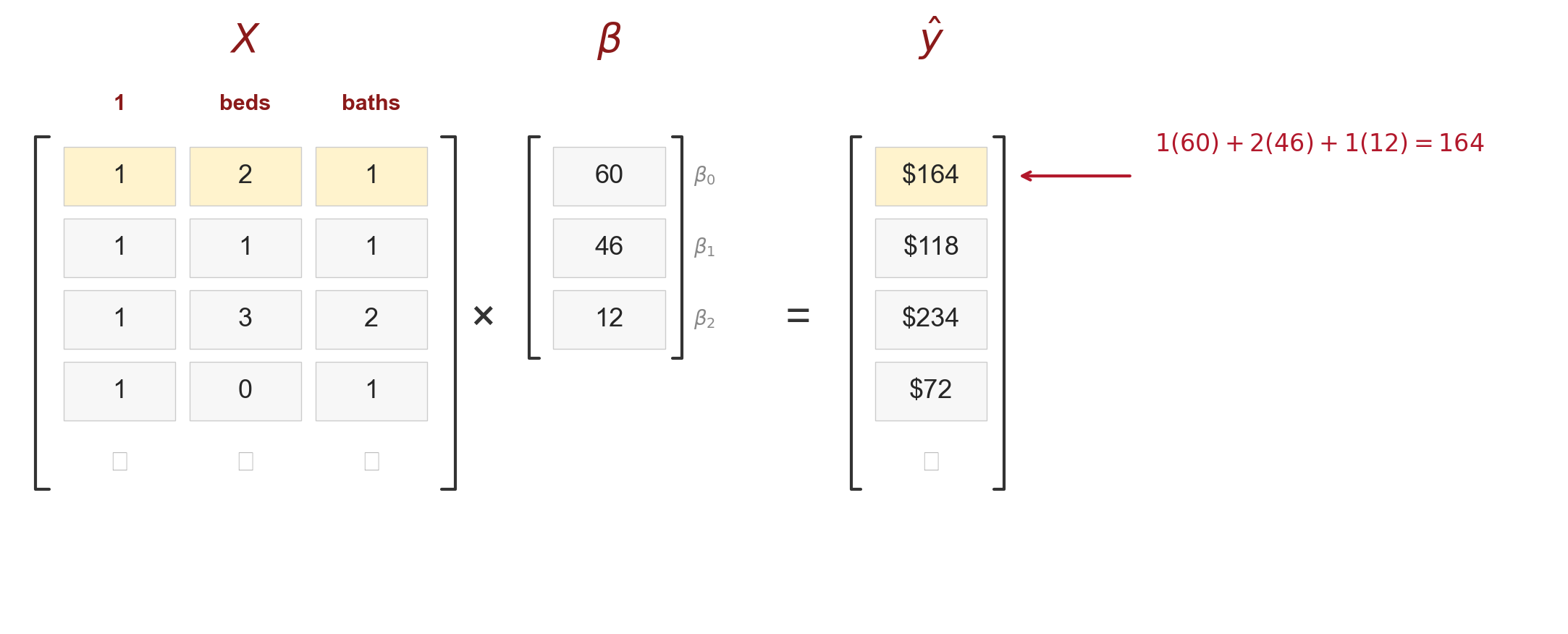
- each row of \(X\) = one listing
- each column = one feature (plus a column of ones)
- \(\widehat{y} = X\beta\) computes all predictions at once
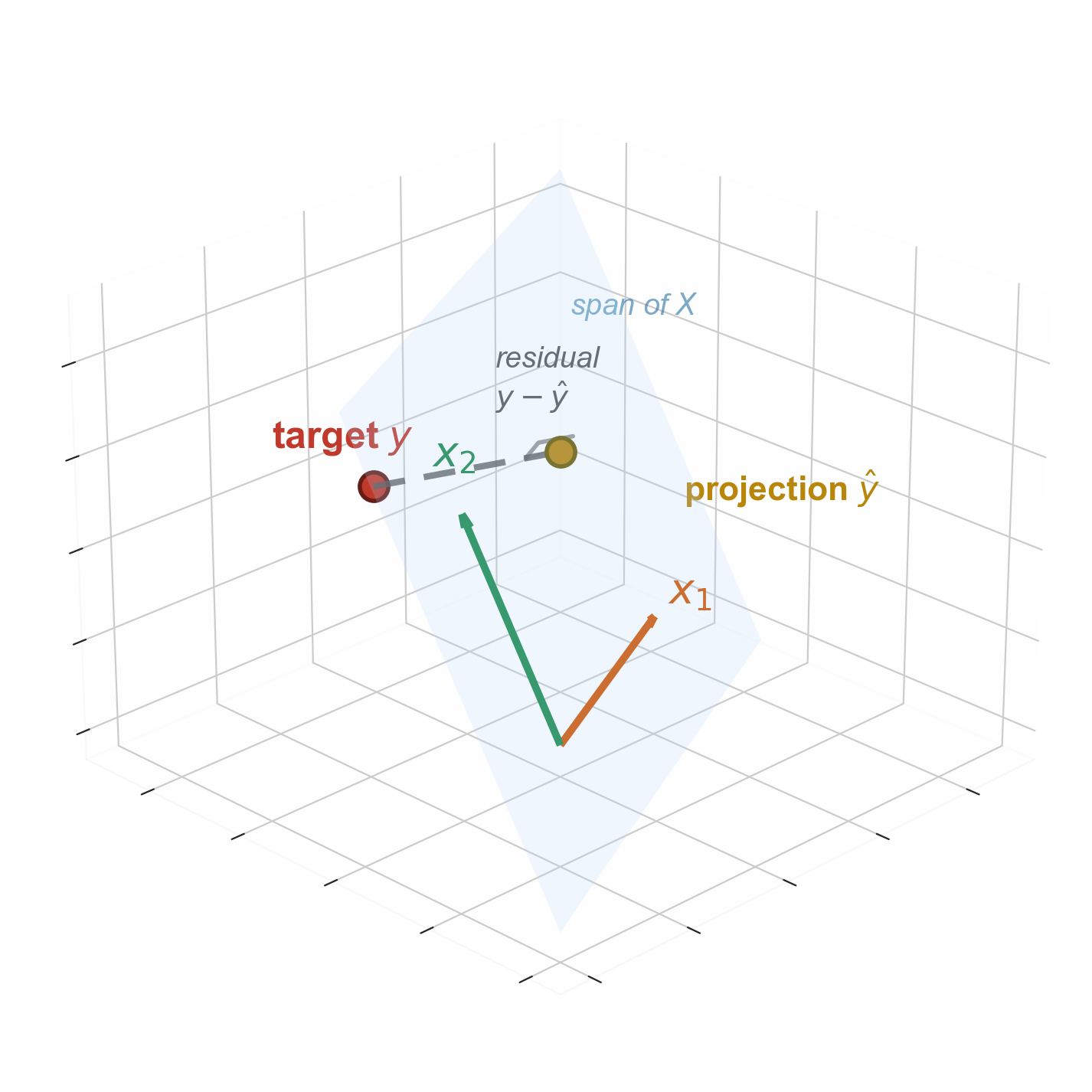
the span grows with more features
\[\text{span}(X) = \{X\beta : \beta \in \mathbb{R}^p\}\]
the set of all possible predictions · the span of the columns of \(X\)
- 1 feature + intercept: 2D plane in \(\mathbb{R}^n\)
- 2 features + intercept: 3D subspace
- more columns → bigger span → closer projection
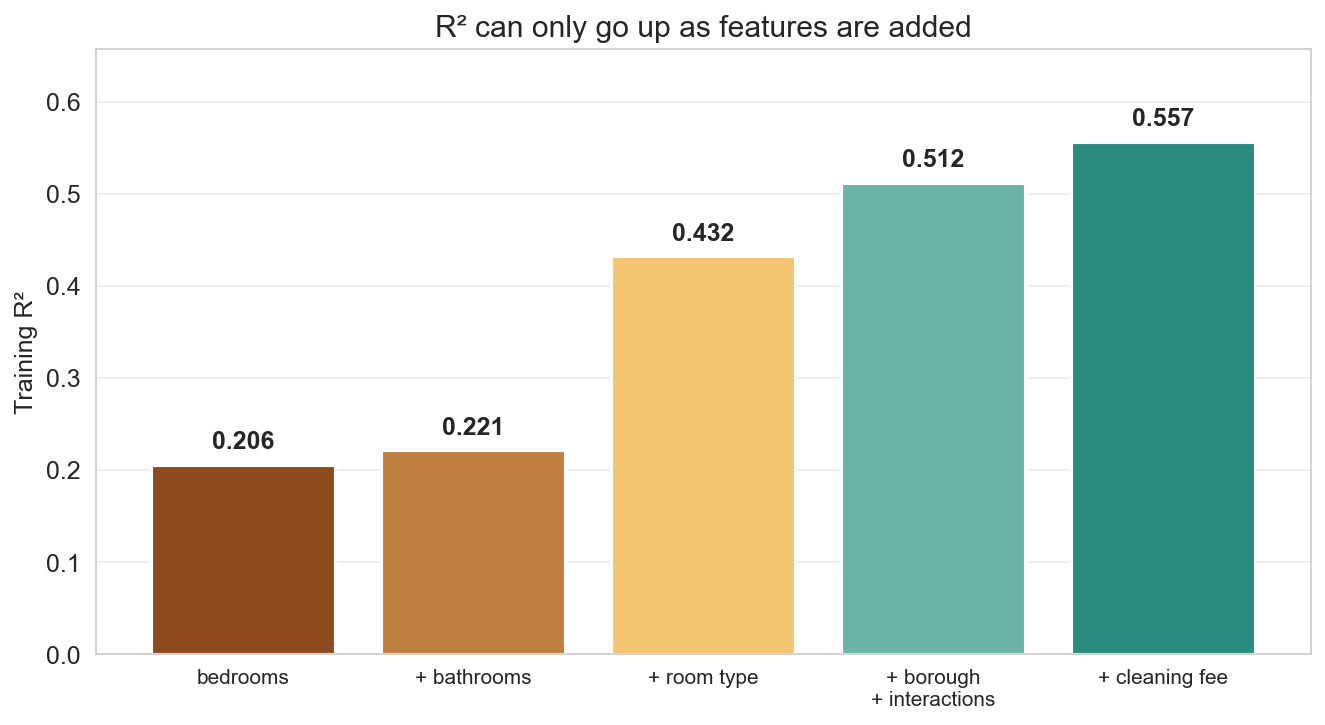
training R² can only go up
adding a feature never decreases training \(R^2\)
- new column → span grows (or stays)
- closer projection → higher \(R^2\)
- \(R^2_{\text{train}}\) is monotonic in # features
danger: \(R^2\) rewards you for adding noise
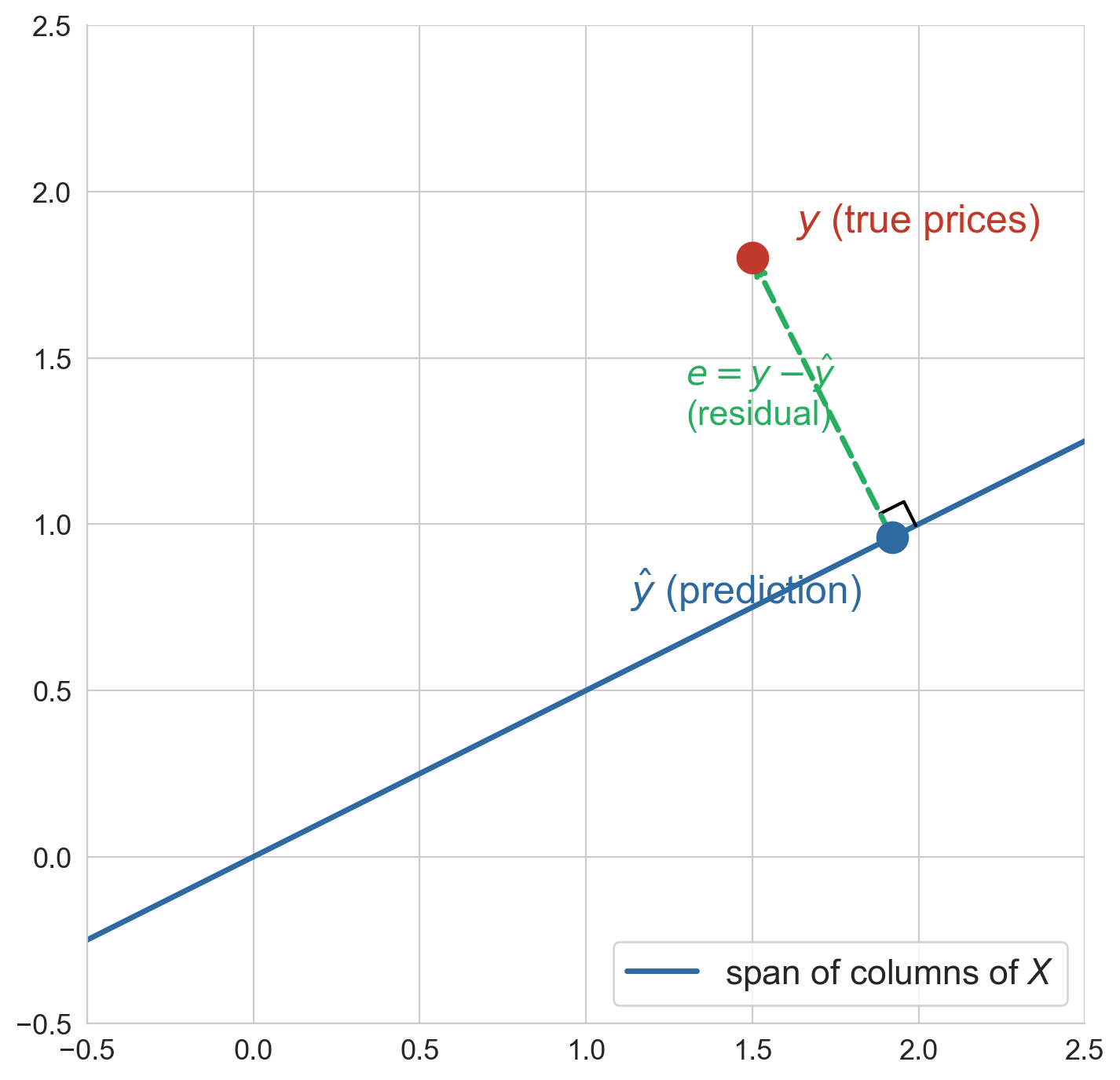
the normal equations
residual orthogonal to every feature column:
\[X^T \epsilon = 0 \quad \text{where } \epsilon = y - X\beta\]
rearrange:
\[X^T X \beta = X^T y\]
\[\widehat{\beta} = (X^T X)^{-1} X^T y\]
closed-form solution for the least-squares coefficients
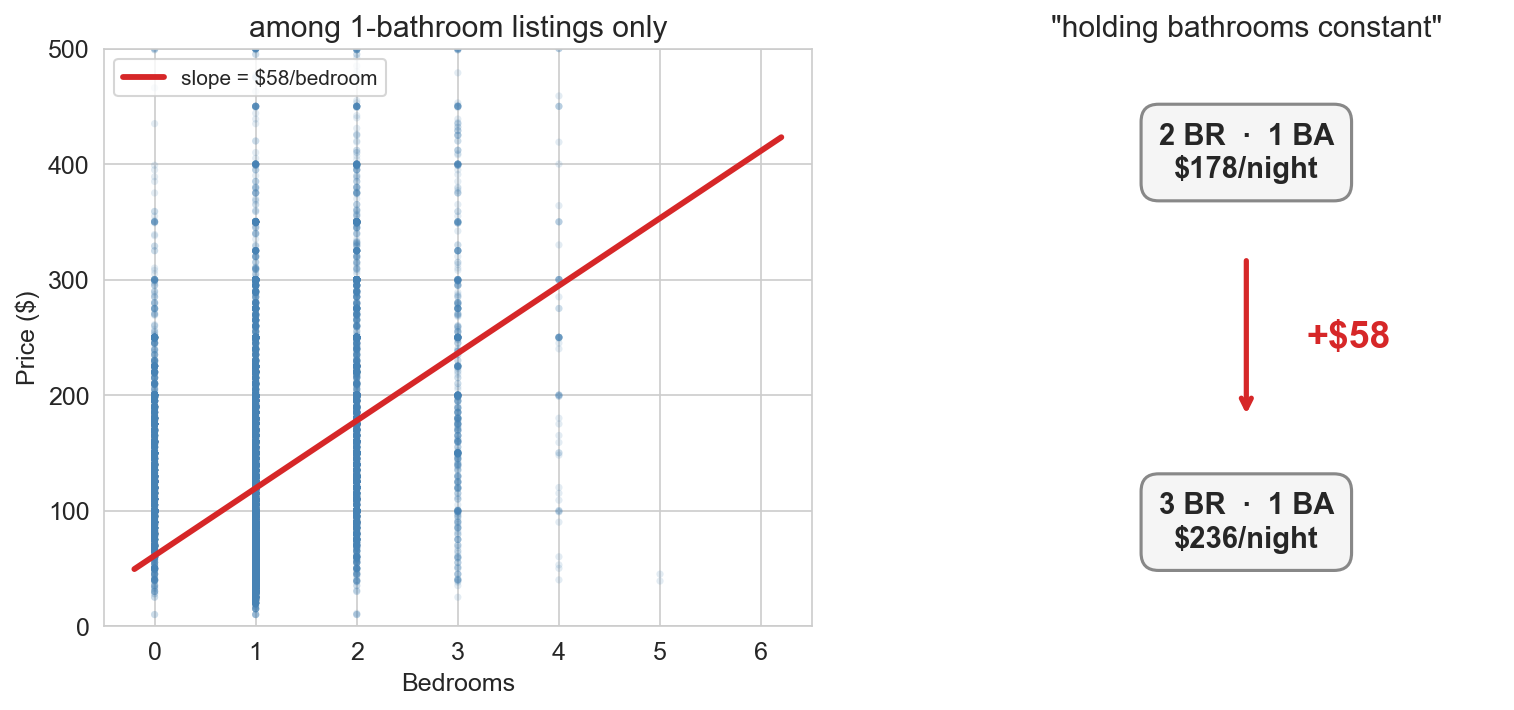
what does the coefficient mean?
\[\widehat{\text{price}} = 27 + \mathbf{58} \times \text{bedrooms}\] \[+ \; 34 \times \text{bathrooms}\]
coefficient = association holding bathrooms constant
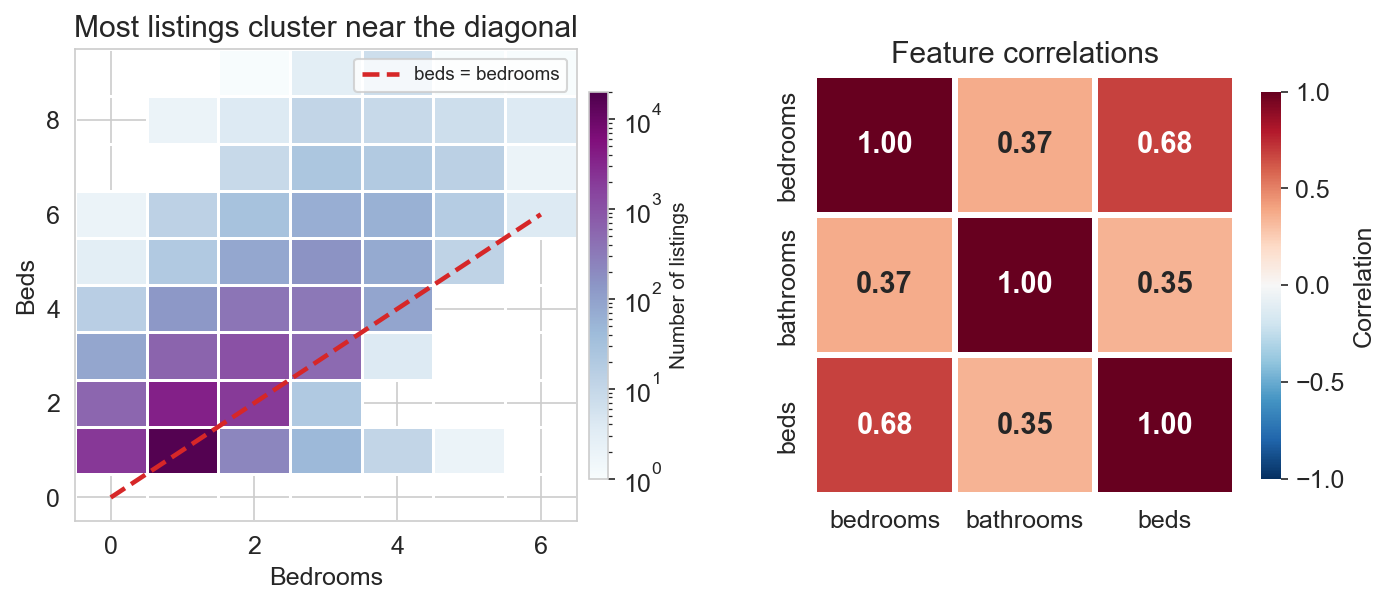
bedrooms and bathrooms travel together
simple regression on bedrooms alone absorbed part of the bathrooms signal
multiple regression disentangles them by holding each constant
these coefficients measure association, not causation
the word for this: confounding (→ Ch 18)
coefficients, visualized
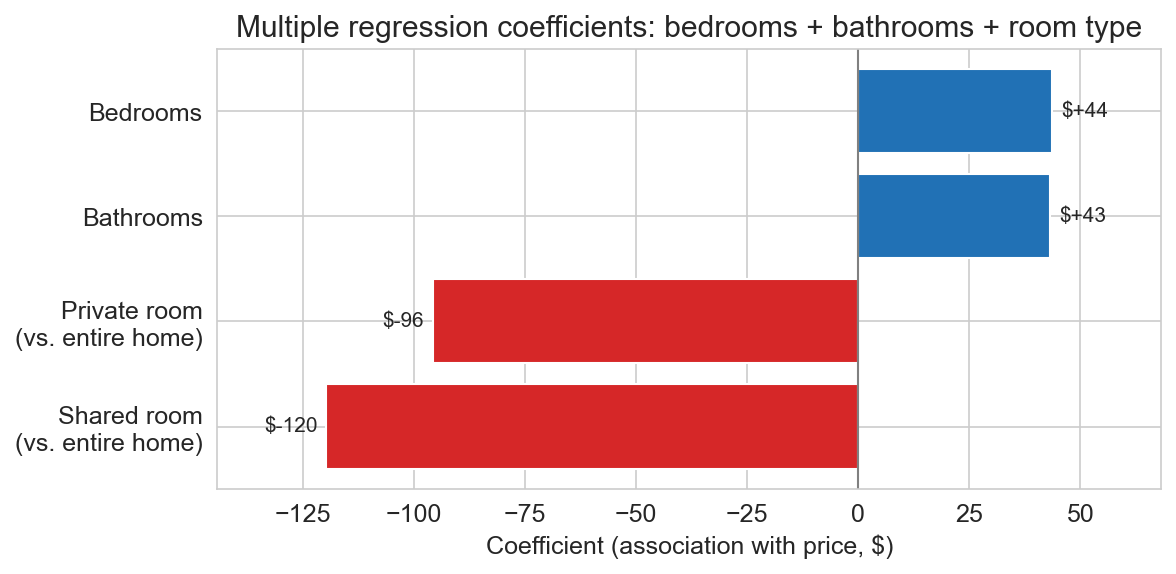
negative bars = discounts from the entire-home baseline · intercept = $81 (the entire-home baseline)
Q: compute the predicted price of a private room, 2 bedrooms, 1 bathroom
\(81 + 44(2) + 43(1) - 96 = \$116\)
interaction terms
is an extra bedroom associated with the same price change in Manhattan and the Bronx?
\[\widehat{y} = \beta_0 + \beta_1 \text{beds} + \beta_2 \mathbf{1}_{\text{Manh}} + \beta_3 (\text{beds} \times \mathbf{1}_{\text{Manh}})\]
where \(\mathbf{1}_{\text{Manh}} = 1\) if Manhattan, \(0\) otherwise
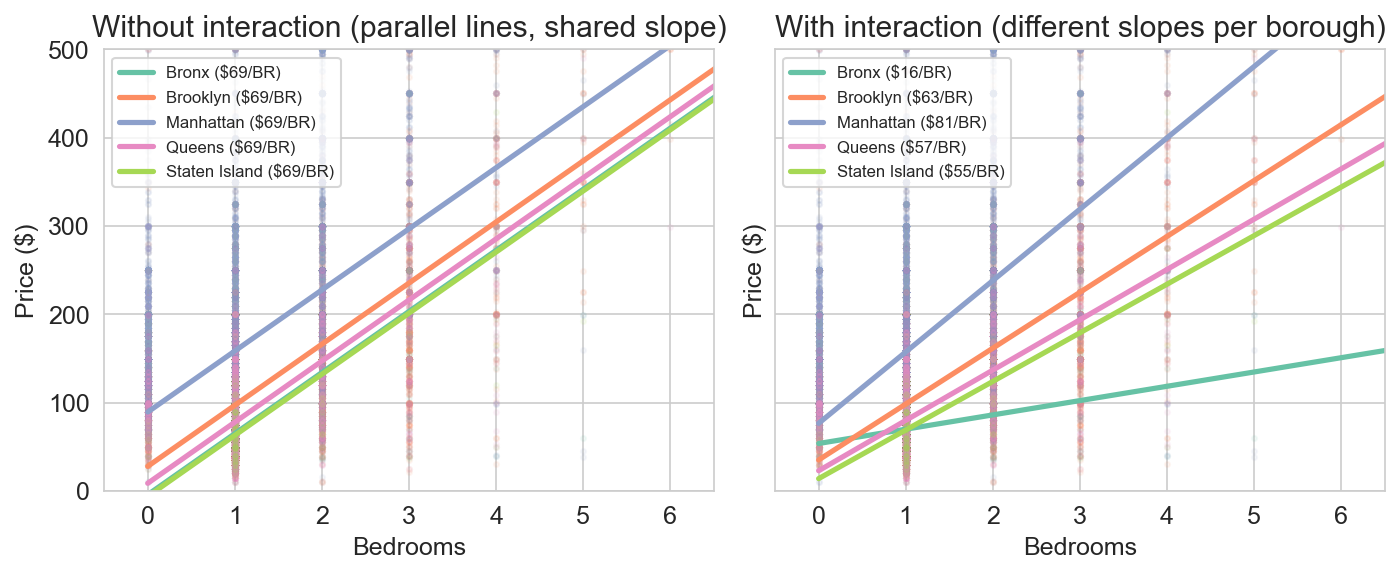
left: without \(\beta_3\), parallel lines · right: with \(\beta_3\), slopes differ by borough
a second clue: the fat right tail
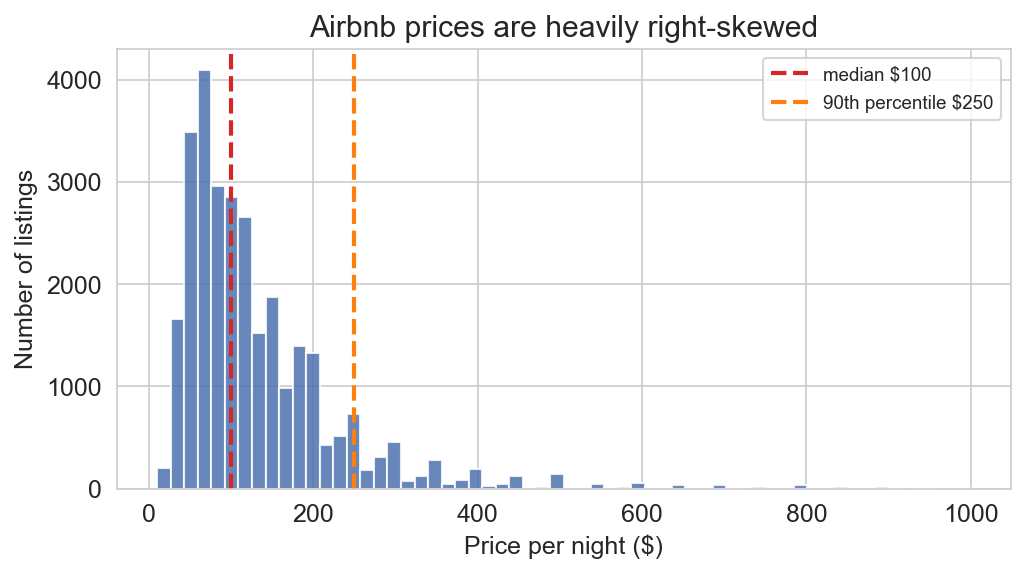
median $100 · 90th percentile $250 · tail runs to $999
the top 5% of listings hold nearly half the level model’s squared error
a $50 miss on $100 (50% off) ≡ a $50 miss on $500 (10% off): squared dollars can’t tell them apart
log transform straightens the curve
ax.set_yscale('log'): log y-axis, same data. level fit curves; log-level fit is straight.
residual diagnostic vocabulary
residual = observed − predicted: \(\epsilon_i = y_i - \hat{y}_i\)
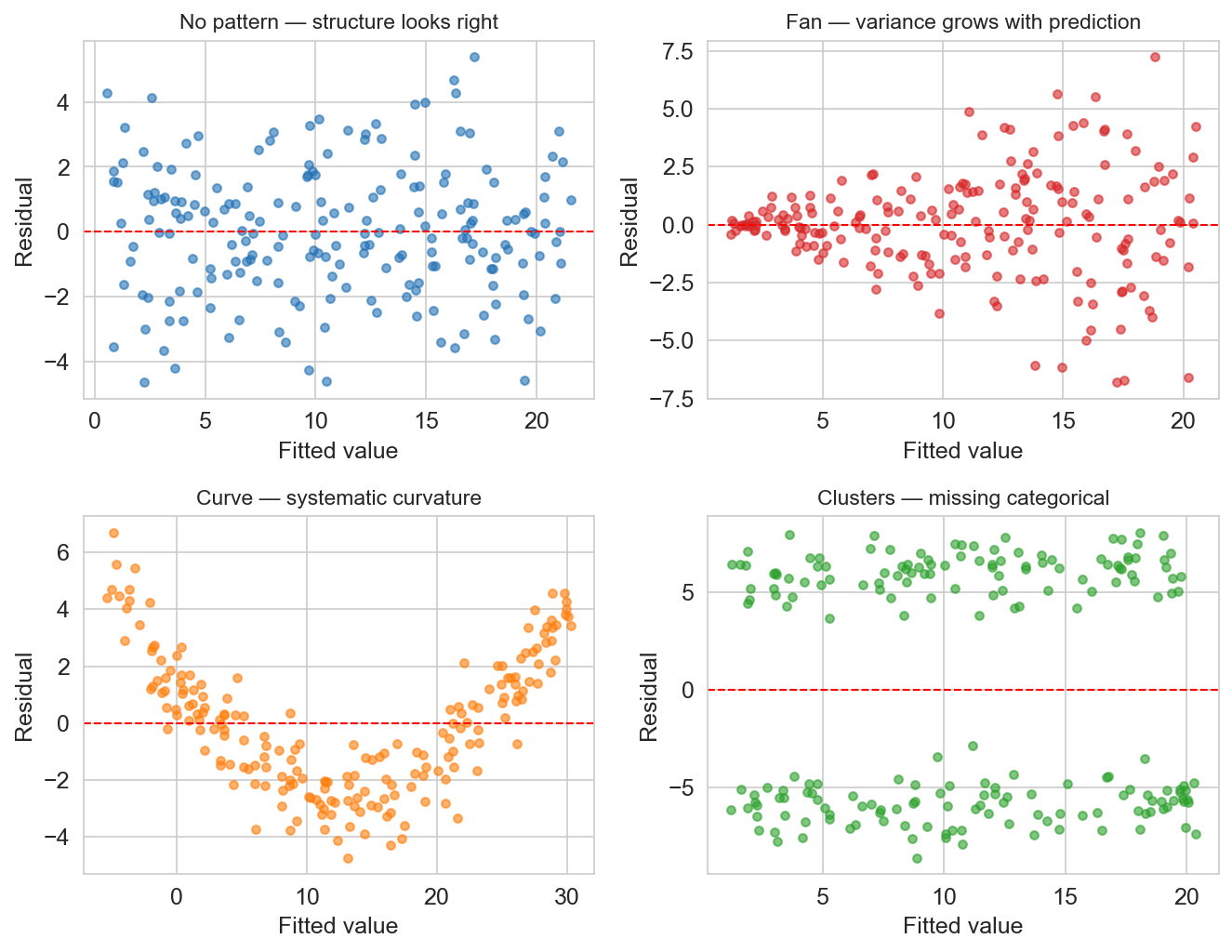
- fan → missing variance-stabilizing transform (often log)
- curve → missing polynomial or log feature
- clusters → missing categorical feature
Airbnb residuals: level vs log
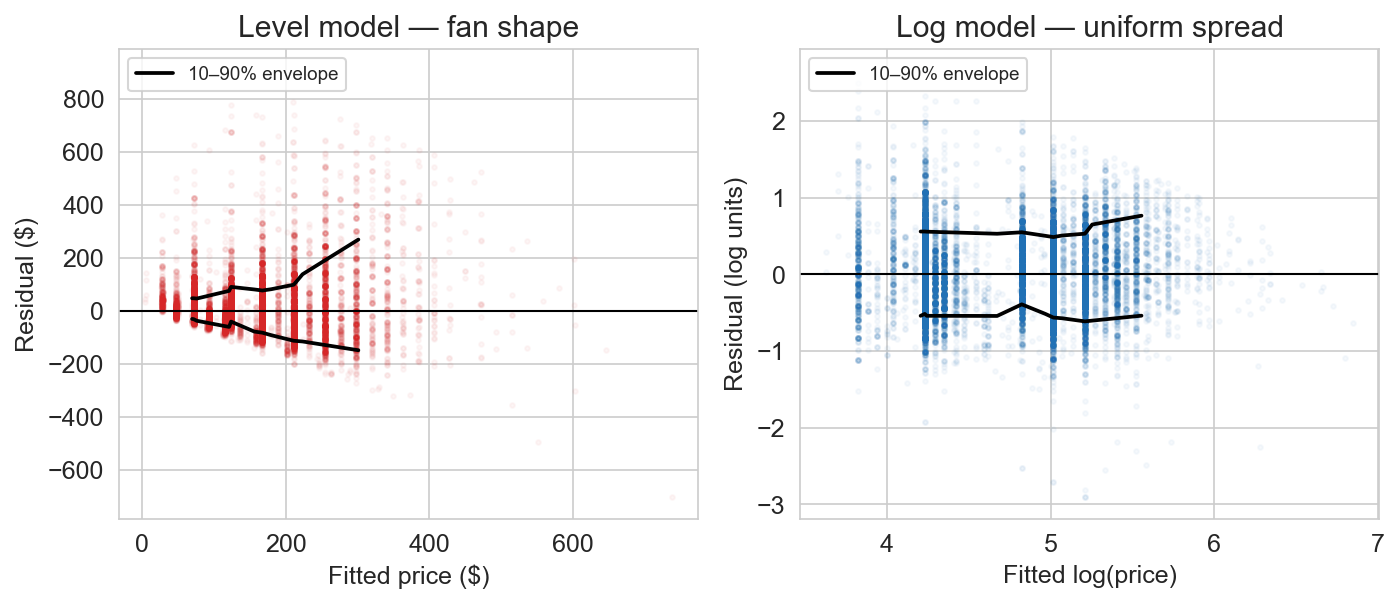
level model: fan from our vocabulary · spread grows with predicted price
log model: flat band · the fan is gone
one-minute feedback
- what was the most useful thing you learned today?
- what was the most confusing?
